前言
本篇文章将优化我自己封装的编辑器,更详细的内容请参考我的编辑器组件封装(一),我项目代码以及简单操作文档我放在了我的git仓库https://gitee.com/guJyang/chat-input-next
@人员追加头像
App.vue
修改列表传参
1 | // @列表 |
At组件中修改样式
1 | <template> |
1 | .at-popover-line-avatar-wrap{ |
信息处理
我们之前只是将内容一直导入到我们的输入框内,但是从来没有将数据导出过,这样的一个富文本编辑框,是不合格的,接下来,我们将数据给导出
- 处理方式:我们可以看到,我们的富文本编辑器内容是有一层一层的div,img,a,文本标签构成的,我们需要将这些标签给解析出来,然后将数据给导出
App.vue中
添加一个方法,用于导出数据
1 | // 得到导出的数据 |
1 | <template> |
chat-input-next.vue中
预备一下处理方法
1 | const {insertImage,insertFile:insertFiles,insertContent,exportMsgData} =useInput({ |
hooks的useInput.ts中
新增ref字段
1 | // 消息msg |
新增预备方法
1 | // 循环子节点 |
ok,接下来,我们就要在loopChildren方法中执行轮询
书写loopChildren方法
去除不必要的标签以及空标签和空文本节点
1
2
3
4
5
6
7
8
9
10
11
12// 循环子节点
const loopChildren = (children: any) => {
// 去除span标签以及无效的文本节点
const filterSpanChildren = Array.prototype.slice
.call(children)
.filter(
(item: any) =>
item.tagName !== "SPAN" &&
Boolean(item) &&
!(item.nodeType === Node.TEXT_NODE && item.textContent === "")
);
}轮询节点并处理文本节点
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27for (let i = 0; i < filterSpanChildren.length; i++) {
// 当前节点
const node = filterSpanChildren[i];
// 如果是文本节点
if (node.nodeType === Node.TEXT_NODE) {
// 获取文本内容
const textContent = node.textContent;
// 如果是多个节点,且不是第一个,那么需要拼接
if (filterSpanChildren && filterSpanChildren.length > 1 && i > 0) {
// 如果前一个节点是a标签,这里我只有@功能是a标签,那么将这段文本和上面一段@的文本拼接,因为@内容也是需要和普通的文本一起展示的
if (
filterSpanChildren[i - 1].nodeType === Node.TEXT_NODE ||
(filterSpanChildren[i - 1].nodeType === Node.ELEMENT_NODE &&
filterSpanChildren[i - 1].tagName === "A")
) {
inputMsgData.value[inputMsgData.value.length - 1] +=
" " + textContent;
} else {
// 多个节点且为第一个
inputMsgData.value.push(textContent);
}
} else {
// 只有一个文本节点,直接添加
inputMsgData.value.push(textContent);
}
}
}处理图片节点
这里是因为我之前添加文件的时候是有一些细节的操作的,不知道大家留意没有,就是普通的图片我是只给了url的,而文件通过domtoimage转化的我是加了imgId的,视频我还加了个type,所以就有了下面这段简单的处理1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19// 图片节点
else if (
node.nodeType === Node.ELEMENT_NODE &&
node.tagName === "IMG"
) {
const imgSrc = node.getAttribute("src");
const imgId = node.getAttribute("id");
const imgType = node.getAttribute("type");
if (imgType === "aov") {
inputMsgData.value.push({ id: imgId, type: "aov" });
}
// 说明是普通文件
else if (imgId) {
inputMsgData.value.push({ id: imgId });
} else {
// 处理图片节点...
inputMsgData.value.push({ url: imgSrc });
}
}换行节点
1
2
3
4// 换行节点
else if (node.nodeType === Node.ELEMENT_NODE && node.tagName === "BR") {
inputMsgData.value.push("\n");
}处理a标签
这里和处理文本节点很类似,然后记得在添加@标签的时候把name给给设置进去1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19// 如果是a标签
else if (node.nodeType === Node.ELEMENT_NODE && node.tagName === "A") {
if (filterSpanChildren && filterSpanChildren.length > 1 && i > 0) {
// 如果上一个节点是@或者文本节点,那么拼上去,不需要添加了
if (
filterSpanChildren[i - 1].nodeType === Node.TEXT_NODE ||
(filterSpanChildren[i - 1].nodeType === Node.ELEMENT_NODE &&
filterSpanChildren[i - 1].tagName === "A")
) {
inputMsgData.value[inputMsgData.value.length - 1] +=
" " + `@${node.getAttribute("nickName")}`;
} else {
inputMsgData.value.push(`@${node.getAttribute("nickName")}`);
}
} else {
inputMsgData.value.push(`@${node.getAttribute("nickName")}`);
}
currentAtUserList.value.push(node.getAttribute("nickName"));
}处理div和p标签
这两个标签很可能是嵌套标签,就是标签里面还有别的标签,因此我们需要特殊处理
- 新增方法判断是否是纯文本进行判断逻辑,如果是纯文本,那么就直接换行添加,如果不是,那么就继续轮询
1
2
3
4
5
6// 判断是否是纯文本
function isPlainText(text: string) {
// 匹配包含html标签的正则表达式
const htmlPattern = /<\s*[^>]*>/gi;
return !htmlPattern.test(text);
}1
2
3
4
5
6
7
8
9
10
11
12
13else if (
node.nodeType === Node.ELEMENT_NODE &&
(node.tagName === "DIV" || node.tagName === "P")
) {
const divContent = node.innerHTML;
// 处理div节点...
if (isPlainText(divContent)) {
inputMsgData.value.push("\n");
inputMsgData.value.push(divContent);
} else {
loopChildren(node.childNodes);
}
}
这里贴出完整的loopChildren的代码
1 | // 循环子节点 |
信息处理
1 | // 导出内容 |
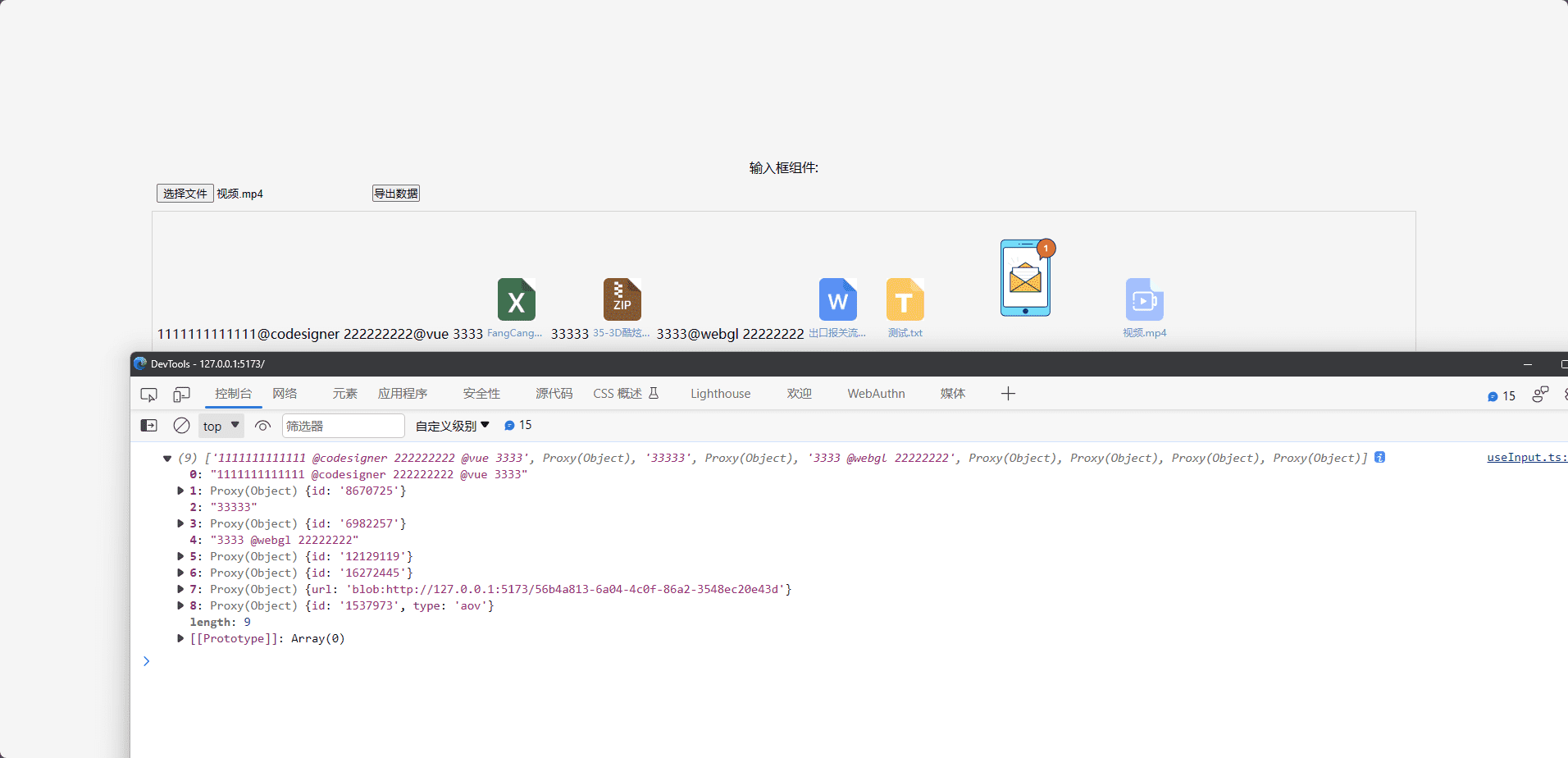
此时,我们已经将数据给导出了
ok,接下来我们将文件和图片的数据对应成file
1 | let msgData:{msg:string;order:number}[]=[] |
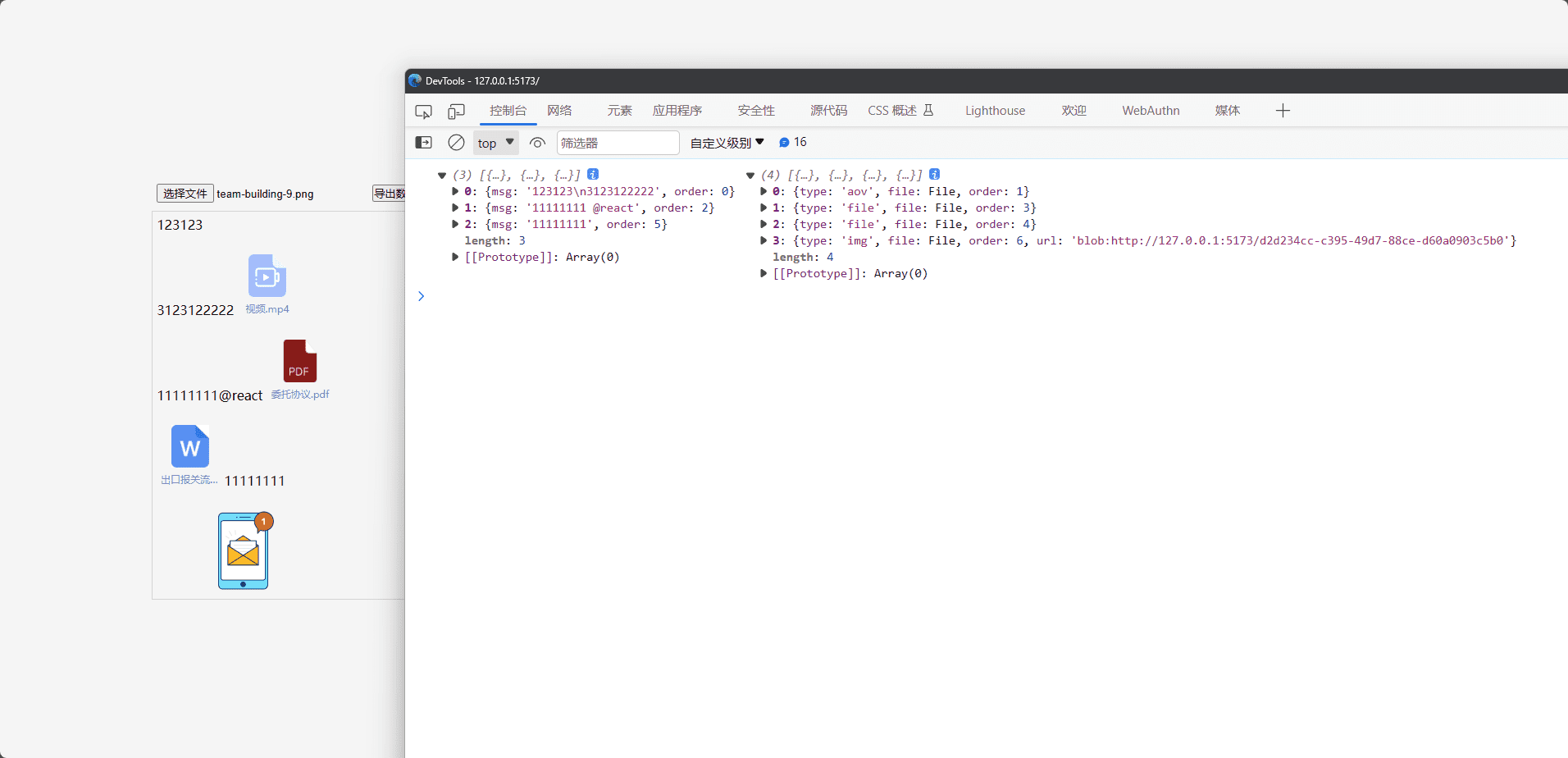
此时,我们的数据就算正式导出了