前言
今天工作比较闲,发现了有这么一个标记的库,感觉挺有意思的,就自己玩了一下,和大家分享一下。
官网地址
地址:https://markjs.io/
纯英文,就咱这英语水平说实话,看这个的确有点费劲。
mark.js尝试
安装并引入
安装
1 | npm i mark.js |
引入
1 | import Mark from "mark.js" |
API使用方式
mark()
官网举例代码:
1 | var context = document.querySelector(".context"); |
keyword
先给大家带来最简单的根据keyword标色的逻辑
- 在这里我们需要给new Mark这个实例化对象的方法传入一个包裹dom
- 然后在这个实例化对象方法的实例instance上,可以传入keyword这个属性,这个属性支持string,array两种。
下面是string的一个demo代码,我这里用了vue3的写法
1 | <script setup> |
效果图就差不多如下:
接下来我把string改成array的类型的demo代码
1 | instance.mark(['天气','错']); |
效果图就差不多如下:
options
他还有第二个参数options,这里我先把官网的table给扒拉下来给大家翻译一下。
| 选项 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| element | string | “mark” | 元素来换行匹配,例如span |
| className | string | “” | 添加到元素的类名 |
| exclude | array | [] | 带有排除选择器的数组。这些元素中的匹配将被忽略。示例:”filter”: [“h1”, “.ignore”] |
| separateWordSearch | boolean | true | 是否搜索以空白分隔的每个单词,而不是搜索完整的词 |
| accuracy | string or object | “partially” | 以下字符串值之一: 1.”partially”: 比如当搜索“lor”时,只会在“lorem”中标记“lor” 2.”complementary”:当搜索“lor”时,整个单词“lorem”都会被标记出来 3.”exactly”:当搜索“lor”时,只有那些具有单词边界的精确单词才会被标记出来。在这个例子中,“lorem”里面没有任何内容。这个值相当于要完美匹配 或者包含两个属性的对象: “value”:上述指定字符串值之一 “limiters”:字符串限制器的自定义数组,以提高准确性 “exactly”或”complementary”。在教程部分阅读更多相关内容 |
| diacritics | boolean | true | 如果应该匹配变音符字符。例如,“piękny”也会匹配“piekny”,“doner”也会匹配“döner”。 |
| synonyms | object | { } | 具有同义词的对象。键将是值和键的值的同义词。例如:”synonym “: {“one”: “1”}将为”one”添加同义词”1”,反之亦然 |
| iframes | boolean | false | 是否也在iframes内部搜索。如果你对某些iframe没有权限(例如,因为它们有不同的起源),它们将被静默跳过。如果你不想搜索特定的iframe(例如facebook共享),你可以传递一个匹配这些iframe的排除选择器 |
| iframesTimeout | number | 5000 | 在跳过iframe之前等待加载事件的最大ms。尤其重要的是,当没有互联网连接或浏览器“离线”模式被启用时,iframe有一个在线src -然后加载事件永远不会被触发 |
| acrossElements | boolean | false | 是否跨元素搜索匹配项 |
| caseSensitive | boolean | false | 是否搜索区分大小写 |
| ignoreJoiners | boolean | false | 是否还查找包含软连字符、零宽度空格、零宽度非拼接符和零宽度拼接符的匹配项。它们用来表示没有足够的空间显示完整单词的换行点 |
| ignorePunctuation | array | [] | 一个标点符号字符串数组。这些标点符号可以在任何字符之间,例如,将此选项设置为[“‘“]将匹配”Worlds”, “World’s”和”Wo’ rds “。字母之间的一个或多个撇号仍然可以产生匹配(例如:”W’o’’r’l’d’s”)这个选项的典型设置如下:”;.,-–—‒_(){}[]!’"+=”.split(“”)” |
| wildcards | string | “disabled” | 设置为以下任意字符串值: “disabled”:禁用通配符 “enabled”:当搜索“lor?”,“?”将匹配零个或一个非空格字符(例如:“lorm”、“loram”、“lor3m”等)。当搜索“lorm”时,“”将匹配零个或多个非空格字符(例如:“lorm”、“loram”、“lor123m”等)。 “withSpaces”:当搜索“lor?”,“?”将匹配0或1个空格或非空格字符(例如:“lorm”、“loram”等)。当搜索“lorm”时,“”将匹配零个或多个空格或非空格字符(例如:“lorm”、“love et dolor ipsum”、“lor: m”等)。 |
| each | function | 每个标记元素的回调。接收标记的DOM元素作为参数 | |
| filter | function | 筛选或限制匹配的回调。它将在每次匹配时被调用,并接收以下参数: 1.包含匹配项的文本节点 2.被发现的术语 3.指示函数调用时所有标记总数的计数器4.记分器,记分器表示一个学期的分数的计数器 如果标记应该停止,函数必须返回false,否则返回true |
|
| noMatch | function | 当没有匹配时将调用的回调函数。接收未找到的项作为参数 | |
| done | function | 所有标记完成后的回调函数。接收作为参数的标记总数 | |
| debug | boolean | false | 如果要记录消息,请将此选项设置为true |
| log | object | console | 将消息记录到特定对象(仅当debug为true时) |
这些属性大家可以自己玩一下,我就不多举例了。
markRegExp()
官网举例代码:
1 | var context = document.querySelector(".context"); |
regexp
我这里也用代码给大家看一下效果就行。
1 | instance.markRegExp(/天气/g); |
此时的效果就是这样
option
参考mark部分,他只有element,className,exclude,iframes,iframesTimeout,acrossElements,each,filter,noMatch,done,debug,log属性,他还有额外的一个属性ignoreGroups,number类型,默认值为0,描述为”指定替换中要忽略的匹配组个数。例如,可以用来实现非捕获的lookbehind组。注意,当值为>0(当组应该被忽略时),它期望在ignoreGroups + 1的RegExp中获得组的总数
markRanges()
官网举例代码:
1 | var context = document.querySelector(".context"); |
ranges
具有起始和长度属性的对象数组。注意,必须指定起始位置,包括空白字符。
这个比较复杂,但是当我们就是一段文字的时候这个可以简单理解为索引,但是当我们的内容中有img等其他dom元素的时候就需要用到window.getSelection()的配合了
1 | instance.markRanges([{ |
此时的效果就是这样
options
参考mark部分,他只有element,className,exclude,iframes,iframesTimeout,each,filter,noMatch,done,debug,log属性
unmark()
官网举例代码:
1 | var context = document.querySelector(".context"); |
options
他的element和className变成了清除这个标记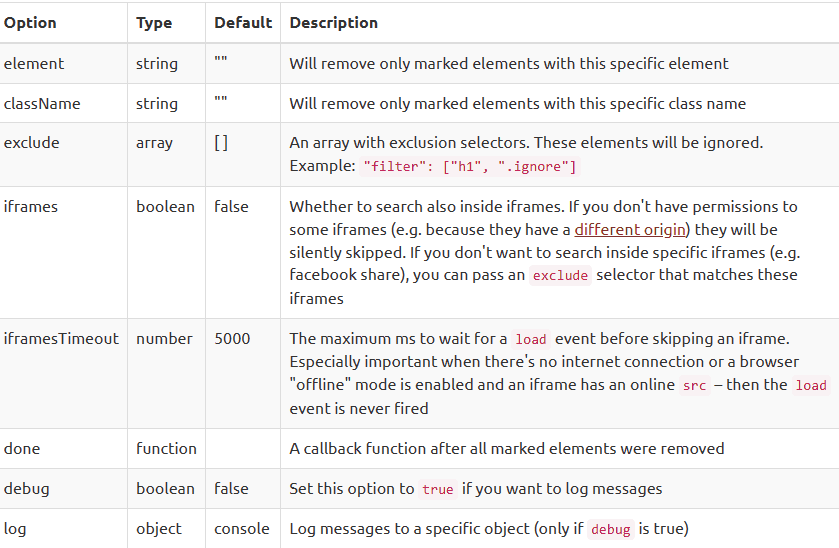
我们将代码修改一下,加个延时器消失
1 | <script setup> |
基于mark.js的小demo
上面我们已经把基础用法都过了一次,接下来我基于这个搞个了demo,大家一起来学习一下。
我先复制了一篇小学生作文:
1 | 20年后的家乡 |
你问我小学生作文咋来,咱就去复制一篇呗,给大家个骚操作
差不多随便搞了点代码就是这样
1 | <script setup> |
完善扩充
我这个demo是有很多问题的,比如选中文字的内容这个逻辑,一篇文章文字肯定是不一样的,所以最好是用markRanges来进行标色,而取值可以用
1 | //获取选取的文字数据 |
然后清空标记我们也可以在添加标记的时候通过each带一个id属性,差不多就是这个样子
1 | instance.markRanges( |
然后我们在清空的时候就可以通过id来清除了,我这里就不详细写了,有兴趣的同学可以自己玩一下。
结语
好了,本篇文章就先到这里了,更多内容敬请期待~



