前言
本篇文章带大家简单了解一下Python爬虫,学习本篇文章要求你先把Python环境给配置好,这个网上文章很多,我就不多介绍了。
爬虫工作原理
爬虫的工作原理是模拟浏览器的工作,对网站的页面进行下载、解析、提取等操作,从而获取到我们想要的数据。具体而言就是:
第0步:获取数据。爬虫程序会根据我们提供的网址,向服务器发起请求,然后返回数据。
第1步:解析数据。爬虫程序会把服务器返回的数据解析成我们能读懂的格式。
第2步:提取数据。爬虫程序再从中提取出我们需要的数据。
第3步:储存数据。爬虫程序把这些有用的数据保存起来,便于你日后的使用和分析。
这就是爬虫的工作原理啦,无论之后的学习内容怎样变化,其核心都是爬虫原理。
体验爬虫
安装requests库
控制台输入pip install requests
pycharm新建项目
注意新建项目需要勾选这俩个,不然pycharm的虚拟环境中是不会有我们安装的requests库的。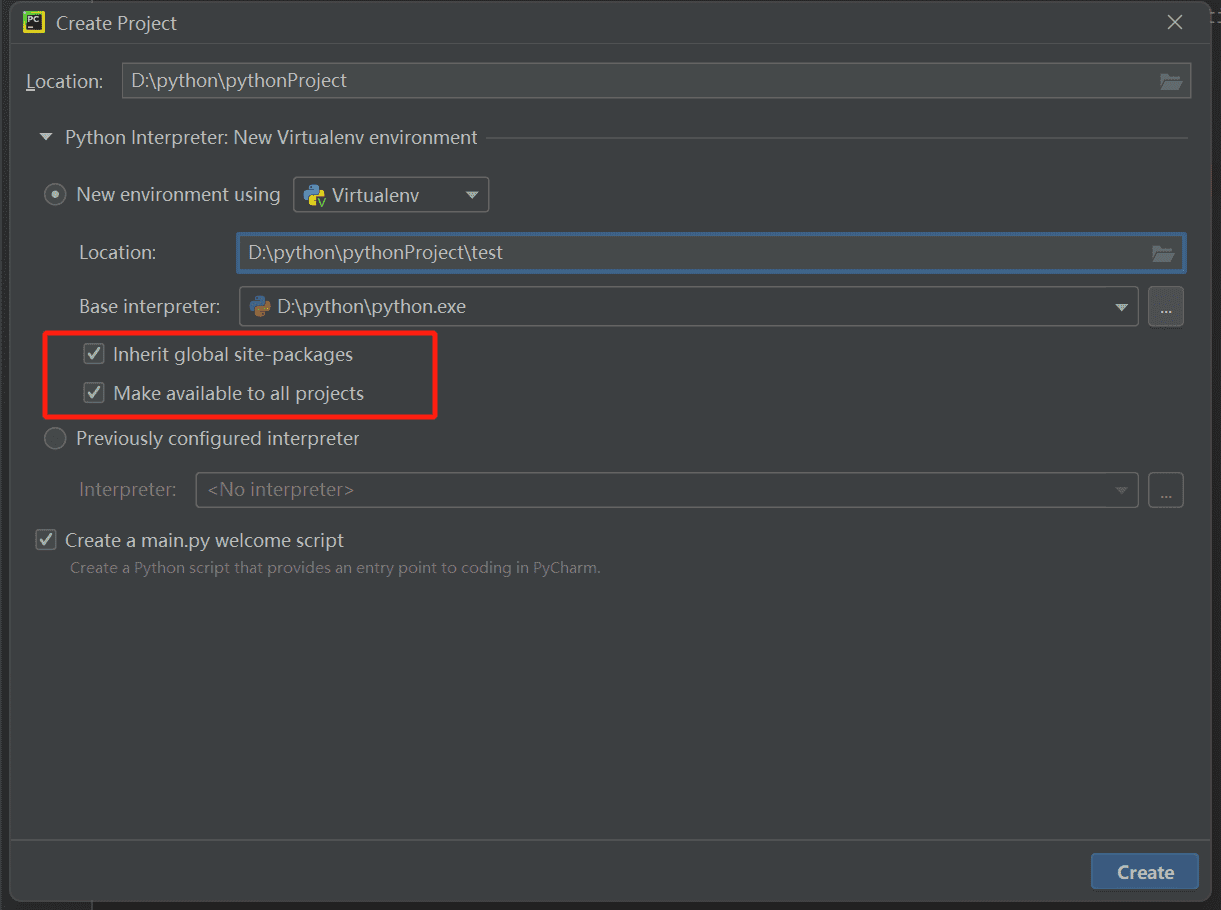
编写代码
我们先爬取人家的一份md文件,代码如下:
1 | # 引入requests库 |
执行完成之后效果如下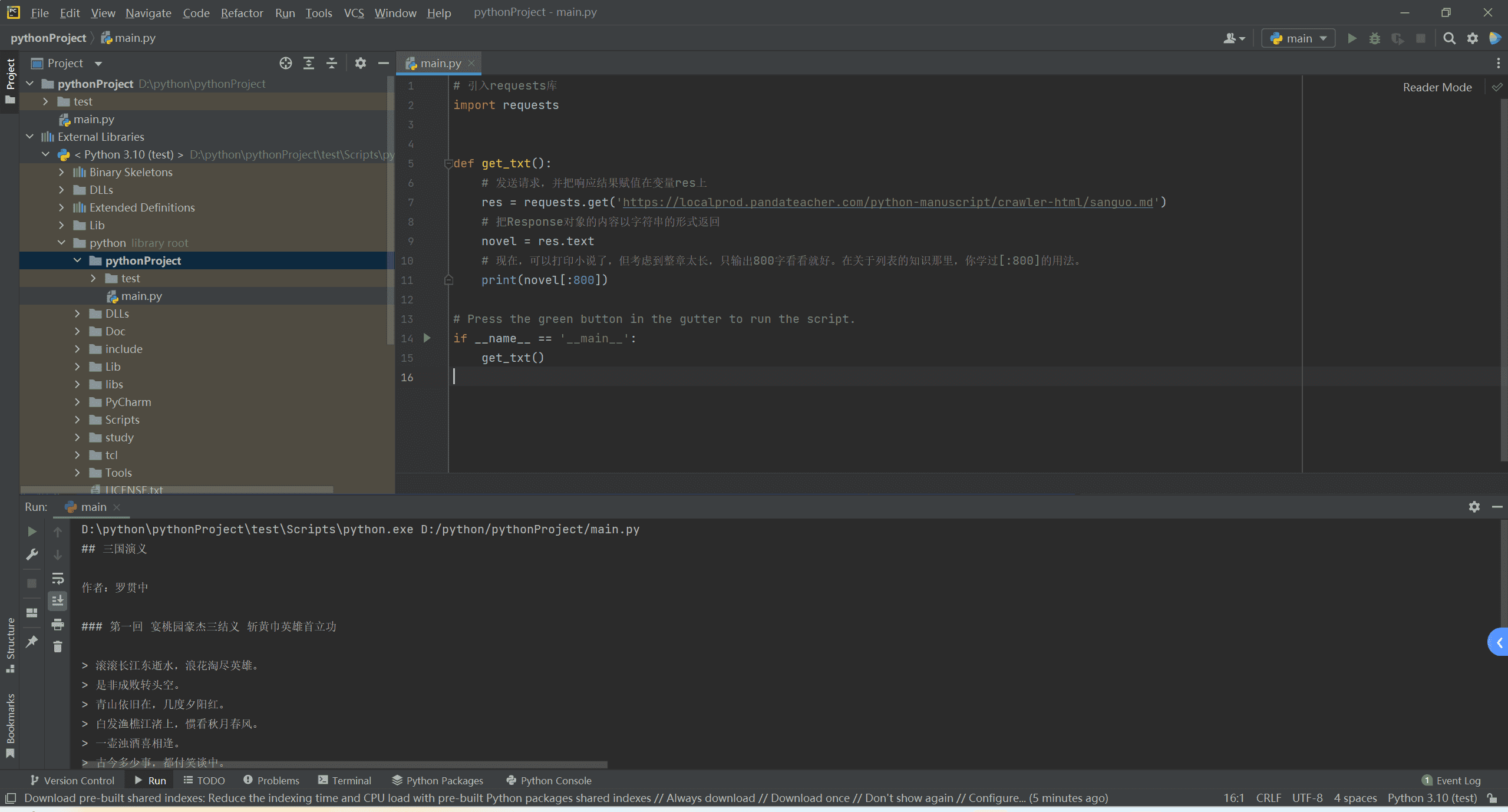
仔细看看代码
这里我们看一下代码,首先我们引入了requests库,然后通过requests.get()方法向服务器发起请求,获取到了服务器返回的数据,然后我们通过res.text方法将数据以字符串的形式返回,最后我们打印出来。
这里给大家贴一下response对象的常用属性和方法:
这里的code就是大家常见的那些状态码,200表示请求成功,404表示请求的资源不存在等等。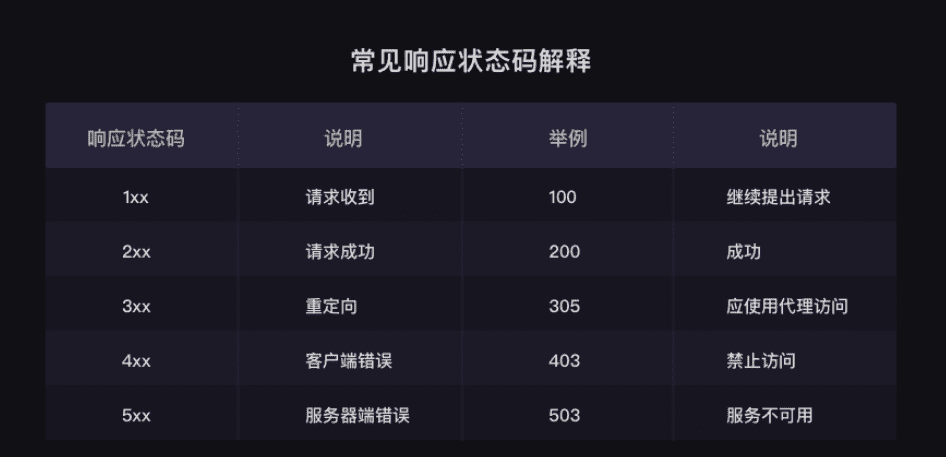
存储数据
我们可以将爬取到的数据存储到本地,代码如下:
1 | # 把Response对象的内容以字符串的形式返回 |
我们通过open()方法创建了一个名为《三国演义》的txt文档,指针放在文件末尾,追加内容,然后通过write()方法将我们爬取到的数据写入到文件中,最后通过close()方法关闭文件。这样操作完重新编译代码之后,我们可以看到本地多了一个txt文档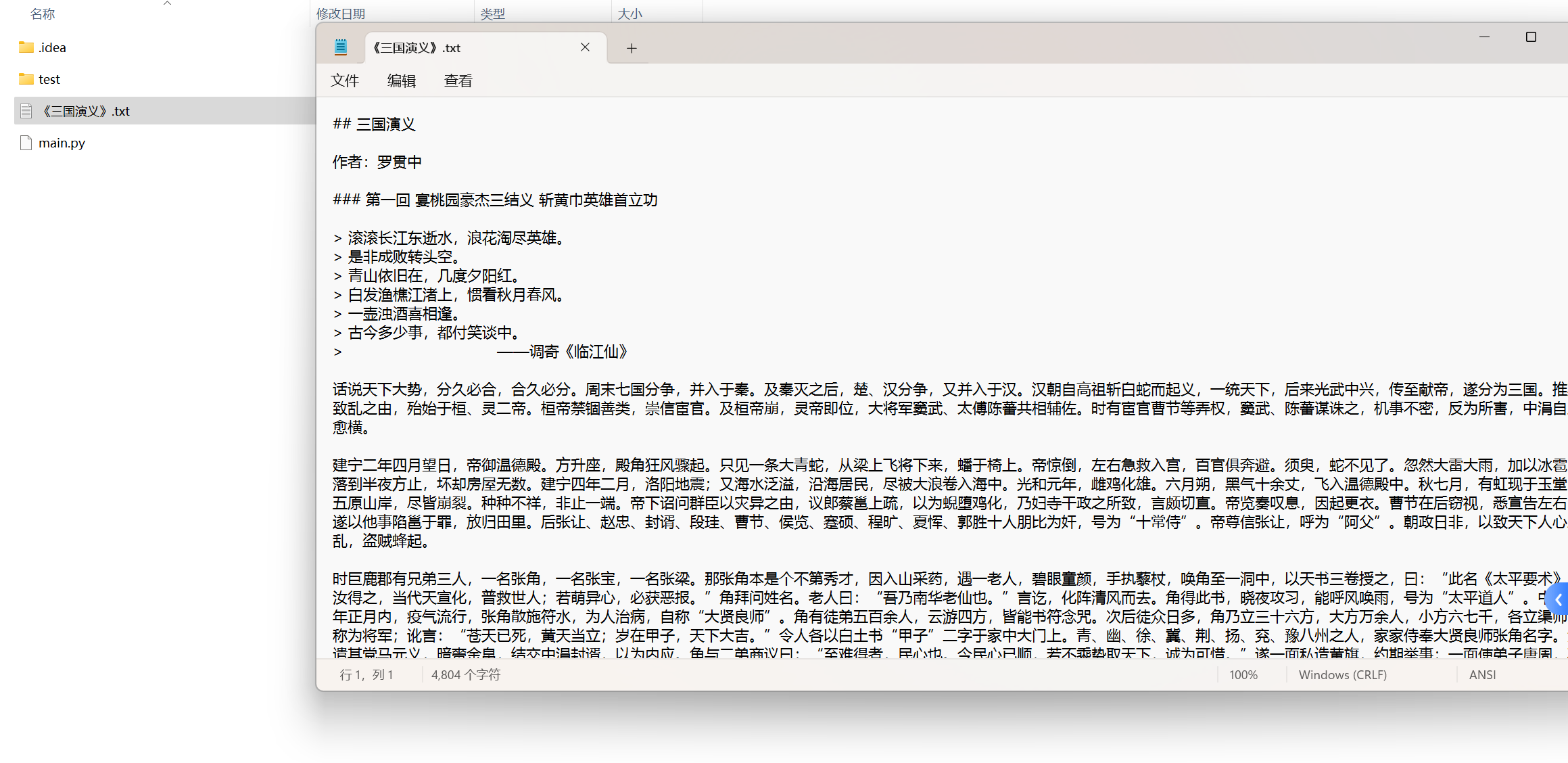
编码格式
当然我们制定我们的编码格式,代码如下:
1 | # res.encoding = 'utf-8' |
爬取图片
再举一个简单的例子,爬取一张图片,这个图片地址需要支持fetch
1 | res = requests.get('https://rocket-chat.oss-cn-hangzhou.aliyuncs.com/202303/999999/imagesb7ab2054257e49c495e2540cd6434705.png') |
此时我们本地就会多了一张图片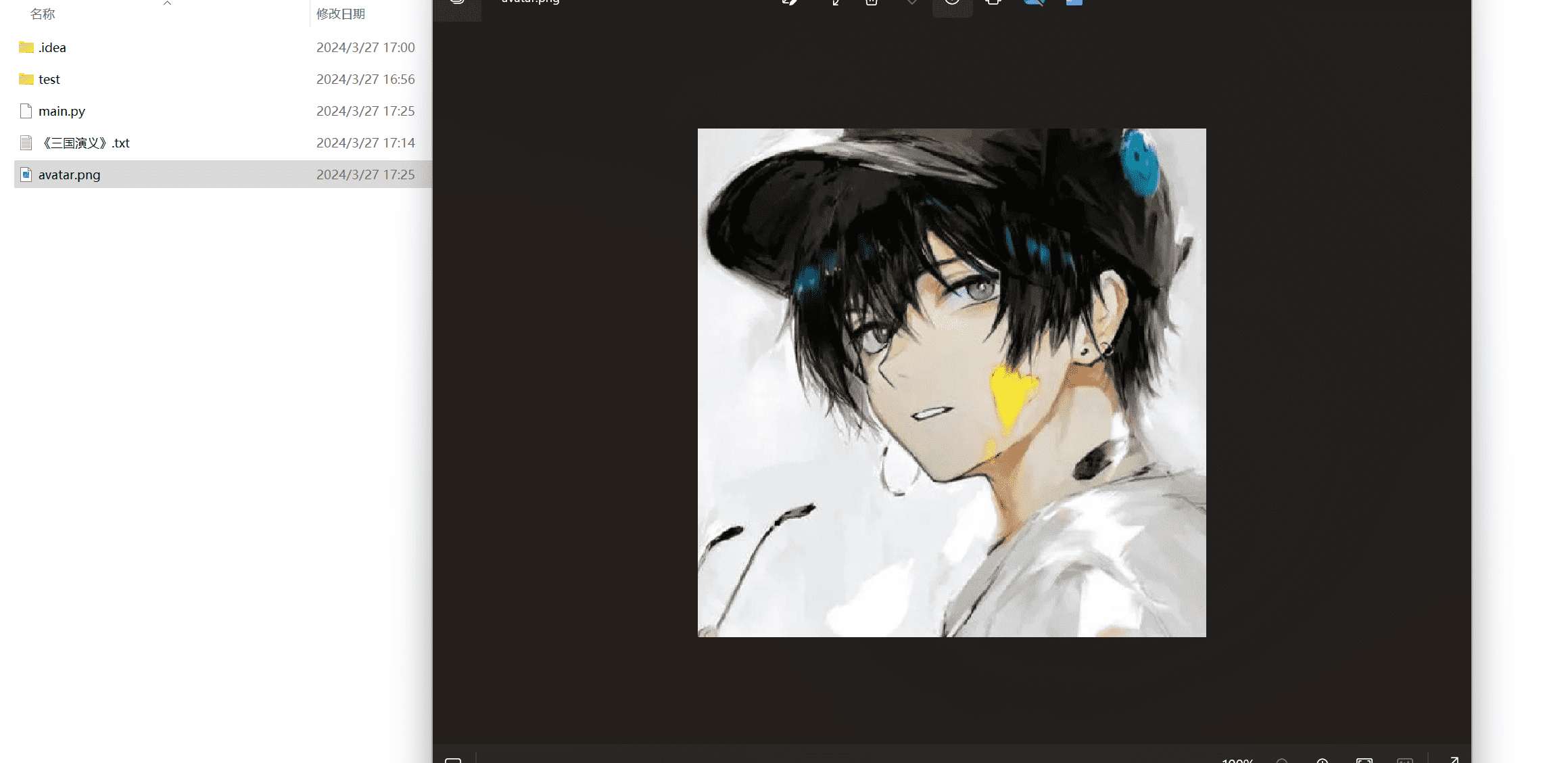
爬虫伦理
这里大家了解一下,别爬着爬着进去了
我截取了一部分淘宝的robots协议 ( http://www.taobao.com/robots.txt)。
在截取的部分,可以看到淘宝对百度和谷歌这两个爬虫的访问规定,以及对其它爬虫的规定。
1 | User-agent: Baiduspider # 百度爬虫 |
可以看出robots协议是“分段”的吗?每个段落都含有以下两种字段:一种是User-agent:,另一种是Allow:或Disallow:。
User-agent表示的是爬虫类型,上面的示例代码注释了“百度爬虫”和“谷歌爬虫”,我们自己写的爬虫一般要看User-Agent: ,指向所有未被明确提及的爬虫。
Allow代表允许被访问,Disallow代表禁止被访问。字段对应的值都含有路径分隔符/,限制了哪些或哪一层目录的内容是允许或者禁止被访问的。可以对比上述百度爬虫Disallow: /product/和谷歌爬虫Allow: /product的注释行理解一下。
比如淘宝禁止其他爬虫访问所有页面,也就是说,我们自己写的爬虫不被欢迎爬取www.taobao.com域名下的任何网页。
有趣的是,淘宝限制了百度对产品页面的爬虫,却允许谷歌访问。
BeautifulSoup
BeautifulSoup是一个灵活又方便的网页解析库,用于解析和提取网页内容。
安装BeautifulSoup
控制台输入pip install beautifulsoup4
使用BeautifulSoup
比如我们这里爬取一下百度的首页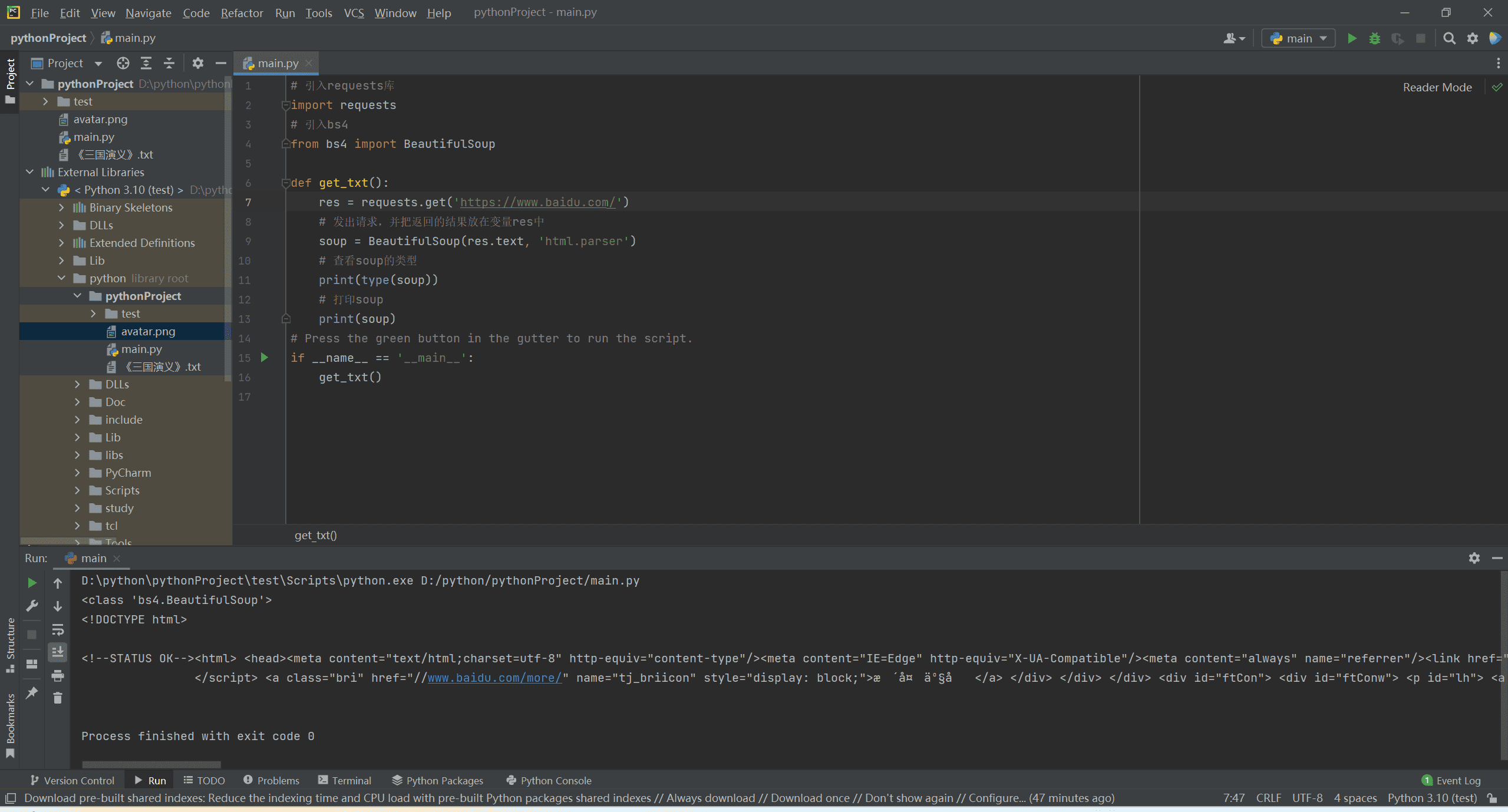
接下来我们可以呀BeautifulSoup自带的功能提取数据
提取数据
find() 和find_all()
find()与find_all()是BeautifulSoup对象的两个方法,它们可以匹配html的标签和属性,把BeautifulSoup对象里符合要求的数据都提取出来。
它俩的用法是一样的,区别在于它们工作量。
find()只提取首个满足要求的数据。find()方法将代码从上往下找,找到符合条件的第一个数据,不管后面还有没有满足条件的其他数据,停止寻找,立即返回。
而find_all()顾名思义(find all:查找全部),提取出的是所有满足要求的数据。代码从上往下找,一直到代码的最后,把所有符合条件的数据揣好,一起打包返回。
比如我们要获取百度这个页面的第一个a标签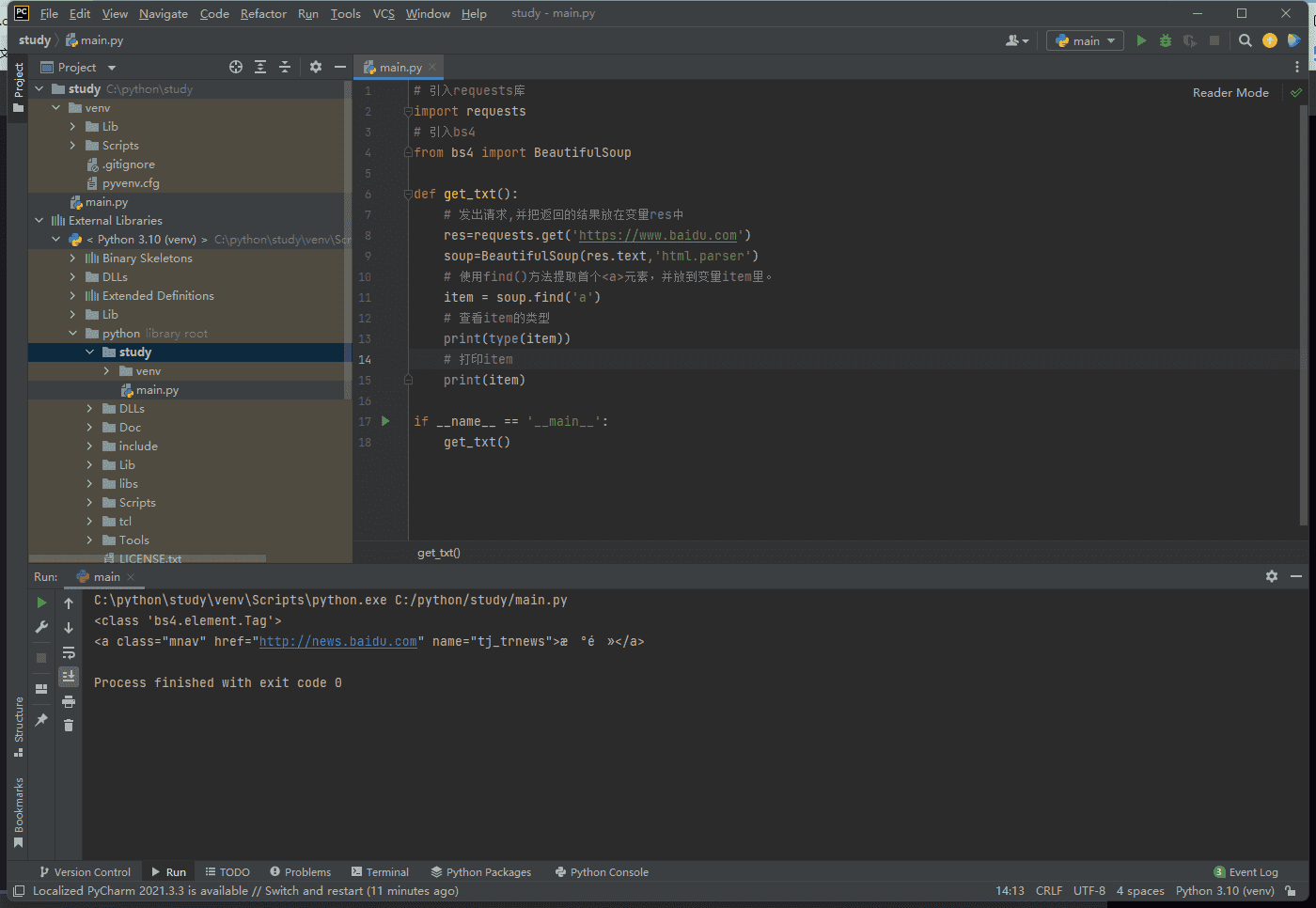
同样道理,我们如果要使用find_all只需要,find进行替换就行
1 | items = soup.find_all('a') |
可能你会说,这不太好理解,其实你按照前端思维理解就很好理解爬虫了,他就是querySelector,querySelectorAll呗
同样的,这俩个函数,可以根据class去得到,比如我们还是获取a标签,但是我这里加了个条件,class是mnav的a标签
1 | items = soup.find_all('a',class_='mnav') |
此时得到的类似于一个list,如果我们要得到每一个标签,就需要使用循环
1 | for item in items: |
这里贴一张图作为这俩个属性的归纳总结
Tag对象
当我们得到某一条dom之后,就需要使用tag对象来获取属性了
大家可以看我这段代码,我获取了a标签之后,将他的内容都给打印了出来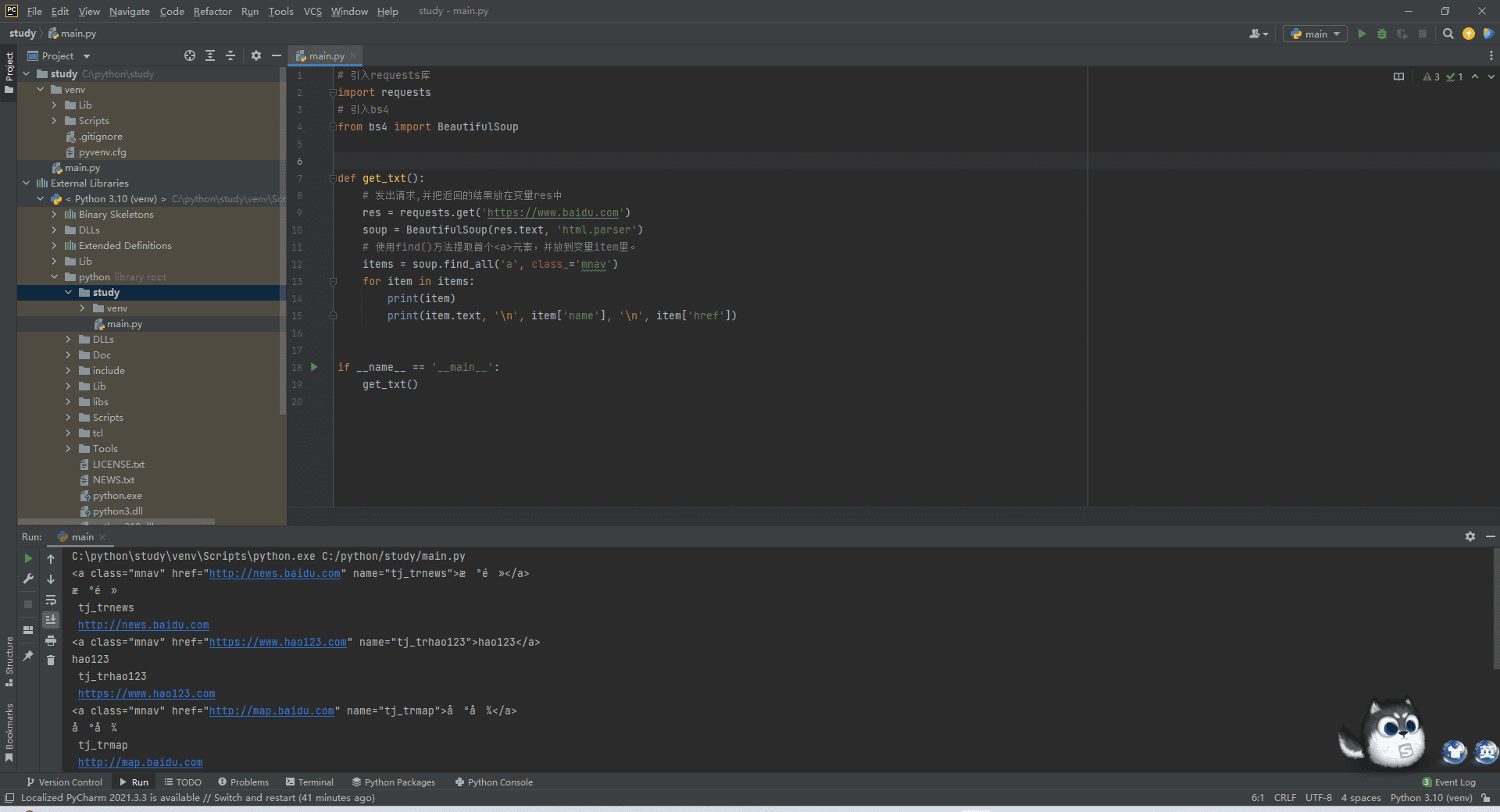
做个简单的测试吧,比如我们要爬cnode的标题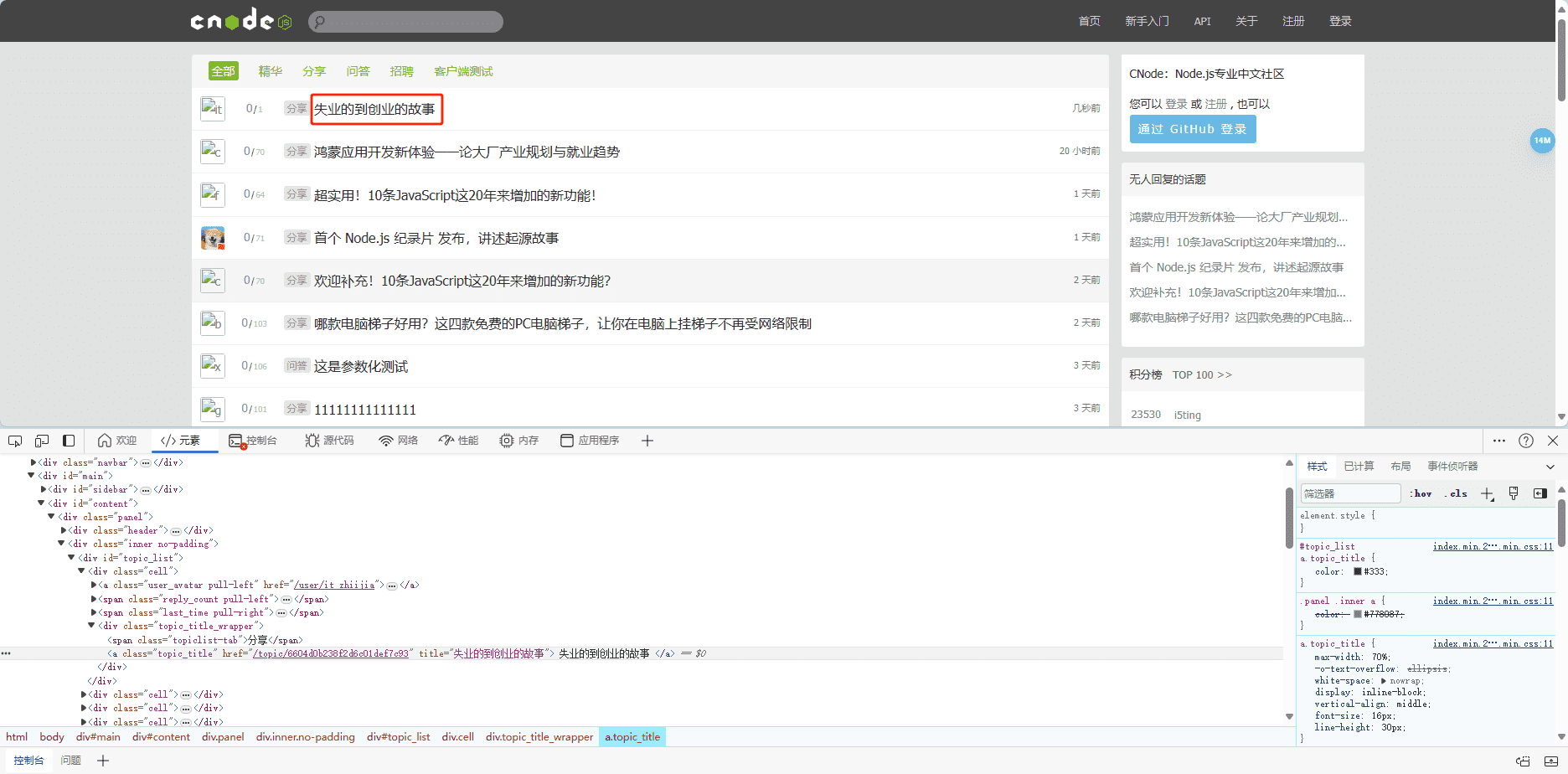
相信我们前端同学对于获取dom内容已经轻车熟路了,这里就按照爬虫的思维获取下dom就行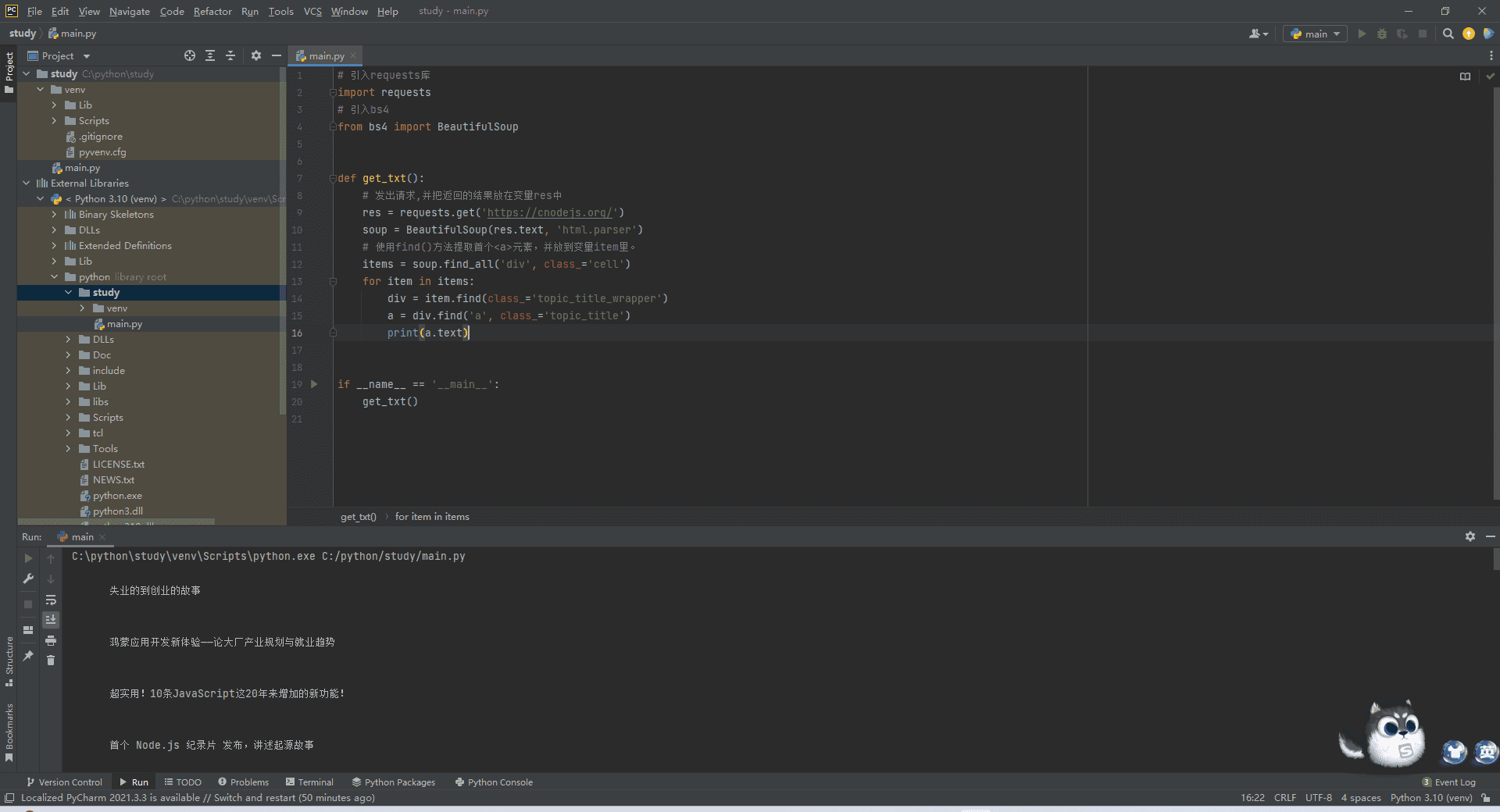
是不是很简单,一层层dom获取下来,最后一层dom的时候我们使用对应的属性即可
爬取豆瓣网
这里简单做个练习题,爬取豆瓣网的电影排行榜,需求是
豆瓣TOP250里面的 序号/电影名/评分/推荐语/链接 都爬取下来,结果就是全部展示打印出来
我们先来简单看一下每一部电影的dom结构,大概是这样的,那么我们就可以尝试着写代码了。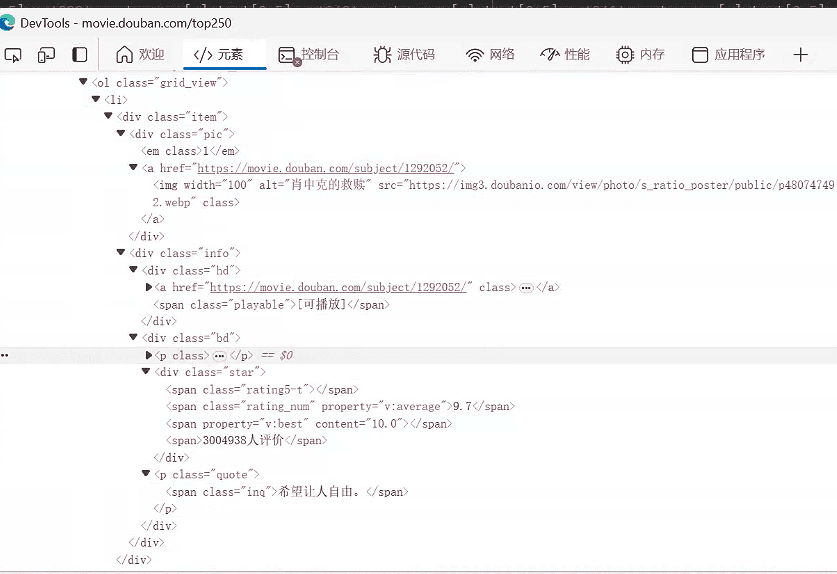
导入库
1 | # 引入requests库 |
设置请求头防止反爬虫
1 | headers = { |
发送请求
1 | url = 'https://movie.douban.com/top250' |
获取所有item标签
我们找一个我们需要内容的父级标签,这里我找了类名为item的div标签,这里答案不唯一,大家可以自己找一个
1 | tag_num = bs.find_all('div', class_="item") |
根据需求找标签
1 | # 查找包含序号,电影名,链接的<div>标签 |
循环获取数据
1 | list_all = [] |
最终代码
1 | headers = { |
此时我们就得到了豆瓣TOP250的电影信息
当然,这里只有一页的电影,我们可以继续优化
获取多页数据并且导出为txt
我们点击第二页,可以看到豆瓣网是通过start参数来控制页数的,那么我们可以通过循环来获取多页数据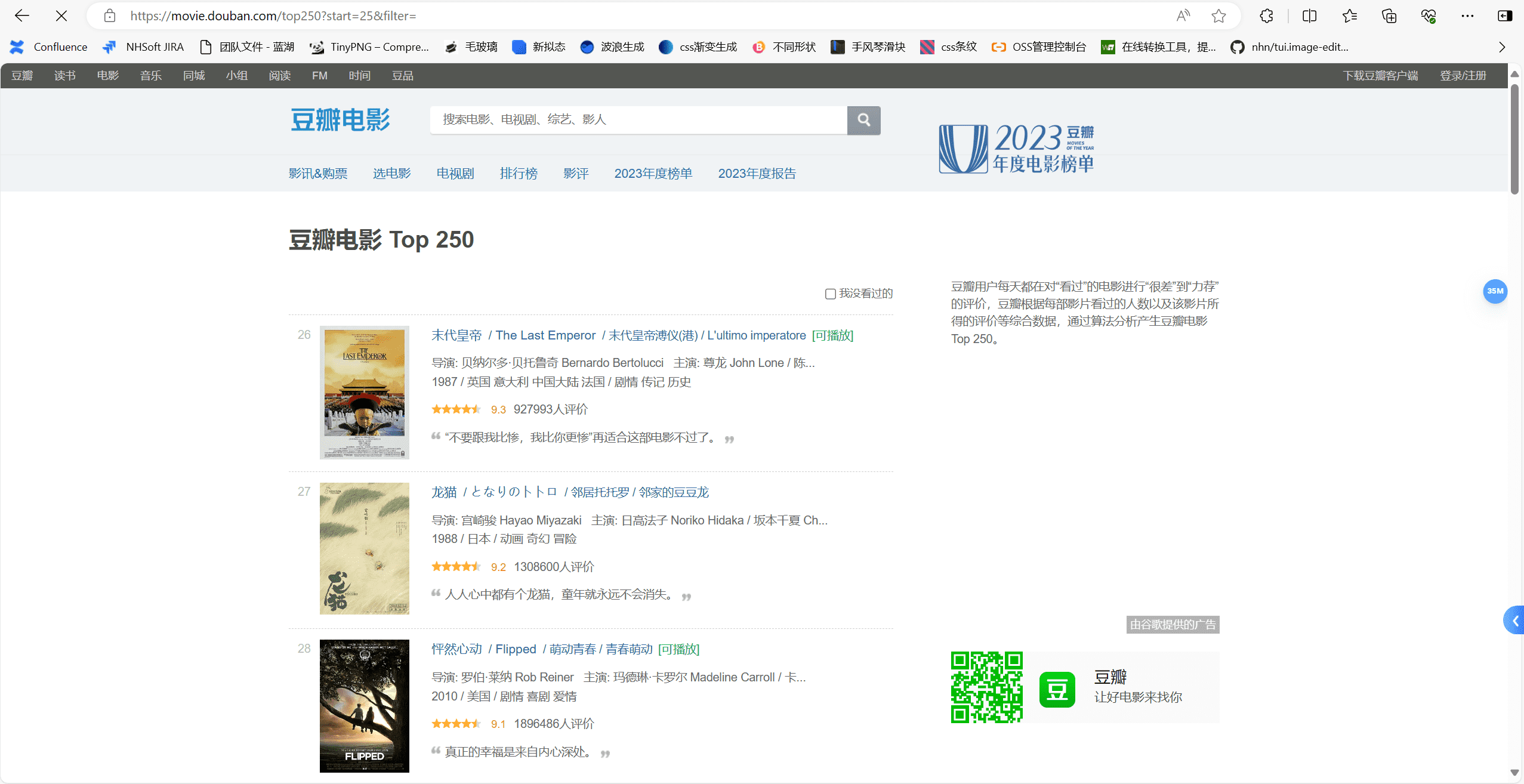
此时代码如下,
这里有个细节,就是tag_word可能为空,所以我们需要判断一下,如果是不存在的话我们需要插入一个默认值,保证代码可以正常运行,不然会导致索引超出tag_word的长度
1 | for y in range(10): |
此时就得到了豆瓣TOP250的电影信息
爬取json数据
有很多网站,数据并不是页面中写死的,而是从ajax发送请求,返回json访问到的,比如我们的CNode的一个接口数据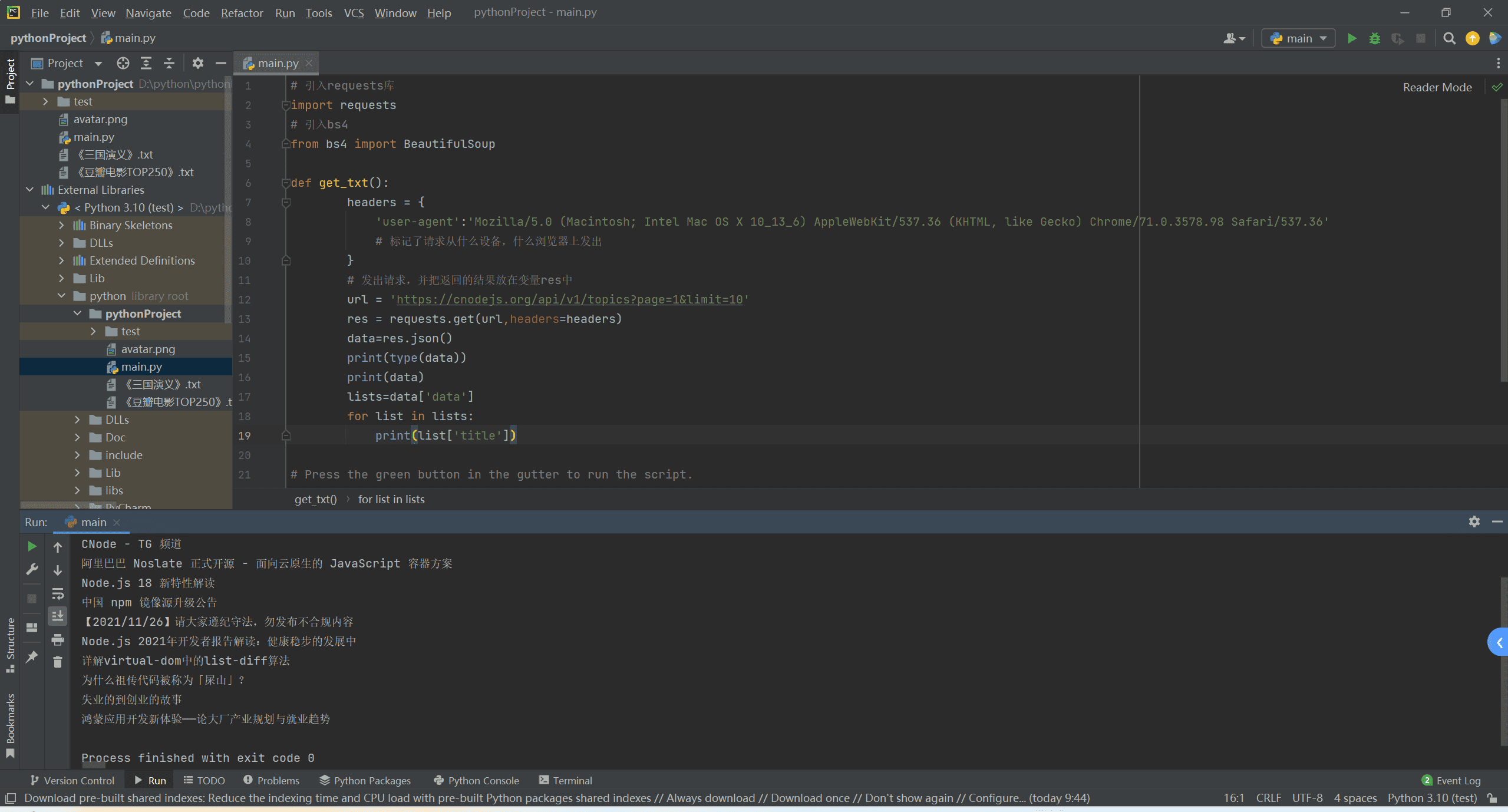
这里的代码我也直接给大家贴一下
1 | headers = { |
当然,我们也可以把请求数据这块写成这样,这里有个细节就是params的key必须加上引号,不然会报错
1 | params={ |
如果是post请求,只需要requests.post,传参用json传递即可,其他的文件之类的各种类型,大家去网上可以查阅文档了解
1 | params={ |
excel和csv的写入读取操作
接下来我们讲解一下,如何将我们爬取下来的数据写入到excel和csv中,毕竟一直使用txt也不是很方便
安装openpyxl
控制台输入pip install openpyxl
引用openpyxl
装好openpyxl模块后,首先要引用它,然后通过openpyxl.Workbook()函数就可以创建新的工作薄,代码如下:
1 | # 引用openpyxl |
获取工作表
创建完新的工作薄后,还得获取工作表。不然程序会无所适从,不知道要把内容写入哪张工作表里。
1 | # wb.active就是获取这个工作薄的活动表,通常就是第一个工作表。 |
写入单个数据
添加完工作表,我们就能来操作单元格,往单元格里写入内容。
1 | # 把'漫威宇宙'赋值给第一个工作表的A1单元格,就是往A1的单元格中写入了'漫威宇宙'。 |
往单元格里写入内容只要定位到具体的单元格,如A1(根据Excel的坐标,A1代表第一列第一行相交的单元格),然后给这个单元格赋值即可。
如果我们想往工作表里写入一行内容的话,就得用到append函数。
1 | # 把我们想写入的一行内容写成列表,赋值给row。 |
写入多行数据
如果我们想要一次性写入的不止一行,而是多行内容
1 | # 先把要写入的多行内容写成列表,再放进大列表里,赋值给rows。 |
保存excel
成功写入后,我们千万要记得保存这个Excel文件,不然就白写啦!
1 | # 保存新建的Excel文件,并命名为“Marvel.xlsx” |
执行代码
说了那么多,我们来执行一下代码
1 | import openpyxl |
此时我们的excel就生成了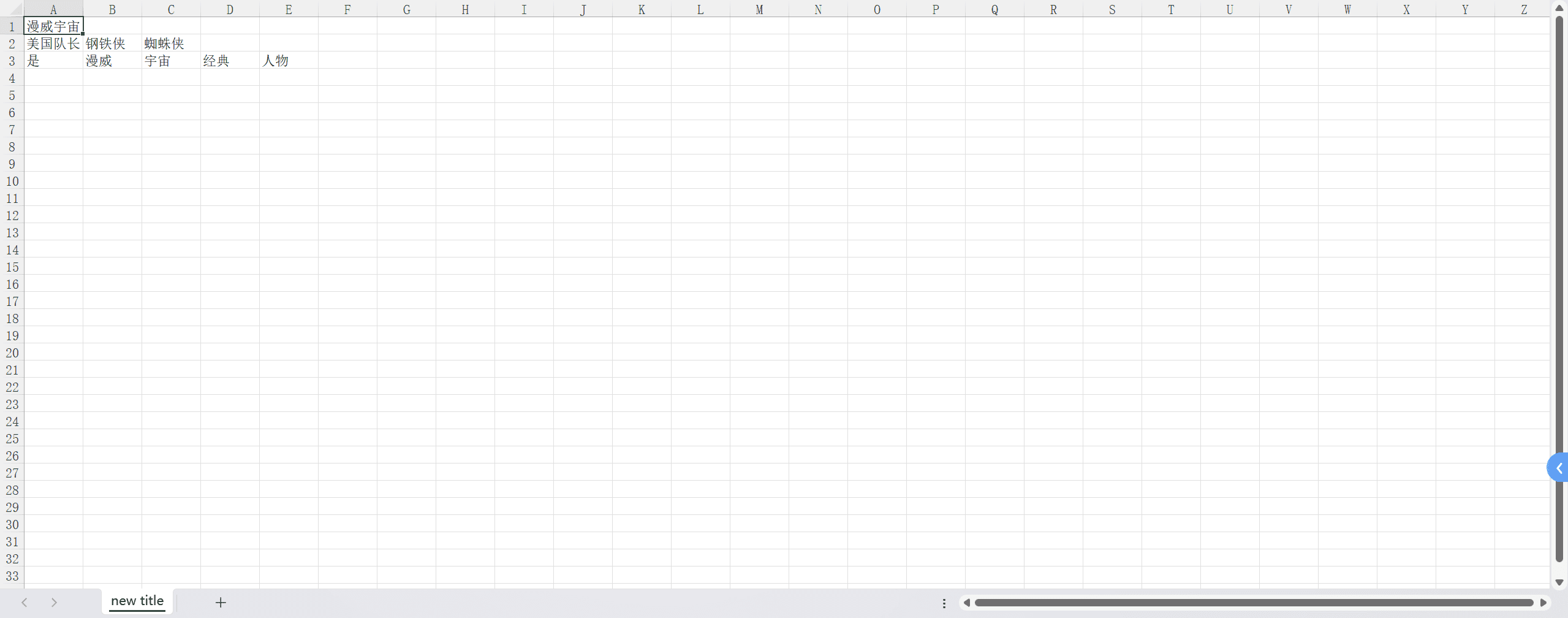
读取excel
1 | # 读取的代码: |
此时我们的excel就读取成功了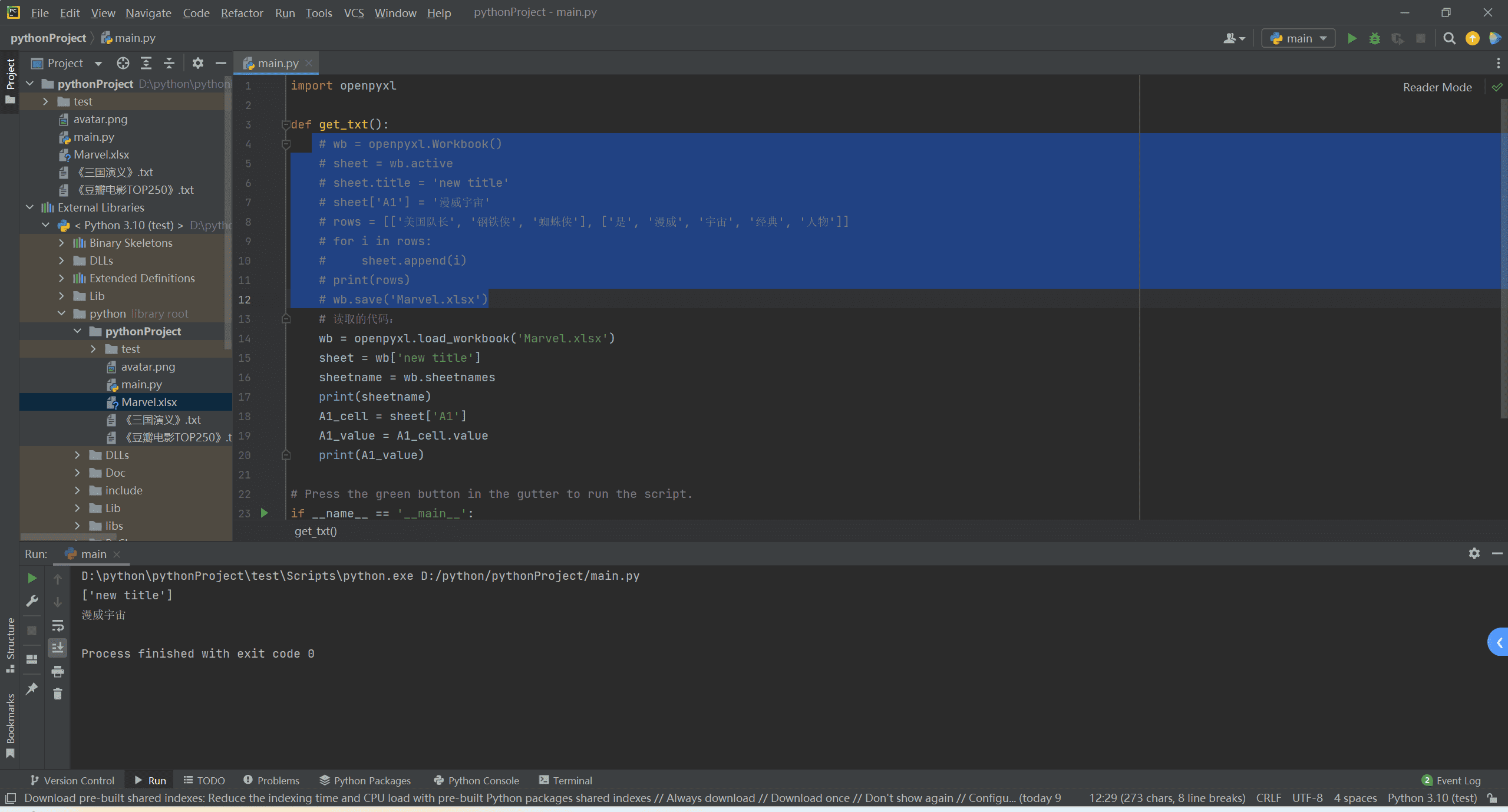
csv的引入
1 | # 引用csv模块。 |
然后,我们得创建一个新的csv文件,命名为“demo.csv”。
“w”就是write,即文件写入模式,它会以覆盖原内容的形式写入新添加的内容。
友情附上一张文件读写模式表。你不需要背下来,之后不知道用什么模式时查查表就可以了。
加newline=’ ‘参数的原因是,可以避免csv文件出现两倍的行距(就是能避免表格的行与行之间出现空白行)。加encoding=’utf-8’,可以避免编码问题导致的报错或乱码。
创建writer对象
创建完csv文件后,我们要借助csv.writer()函数来建立一个writer对象。
1 | # 引用csv模块。 |
写入csv
那怎么往csv文件里写入新的内容呢?答案是——调用writer对象的writerow()方法。
1 | # 借助writerow()函数可以在csv文件里写入一行文字 "电影"和“豆瓣评分”。 |
提醒:writerow()函数里,需要放入列表参数,所以我们得把要写入的内容写成列表。就像[‘电影’,’豆瓣评分’]。
我们试着再写入两部电影的名字和其对应的豆瓣评分,最后关闭文件,就完成csv文件的写入了。
1 | # 引用csv模块。 |
读取csv
1 | import csv |
练习
这里我们做个小练习,把我们爬取到的豆瓣TOP250的数据写入到csv中和excel中
1 | import requests |
这是我的代码,大家可以自己尝试一下,看看效果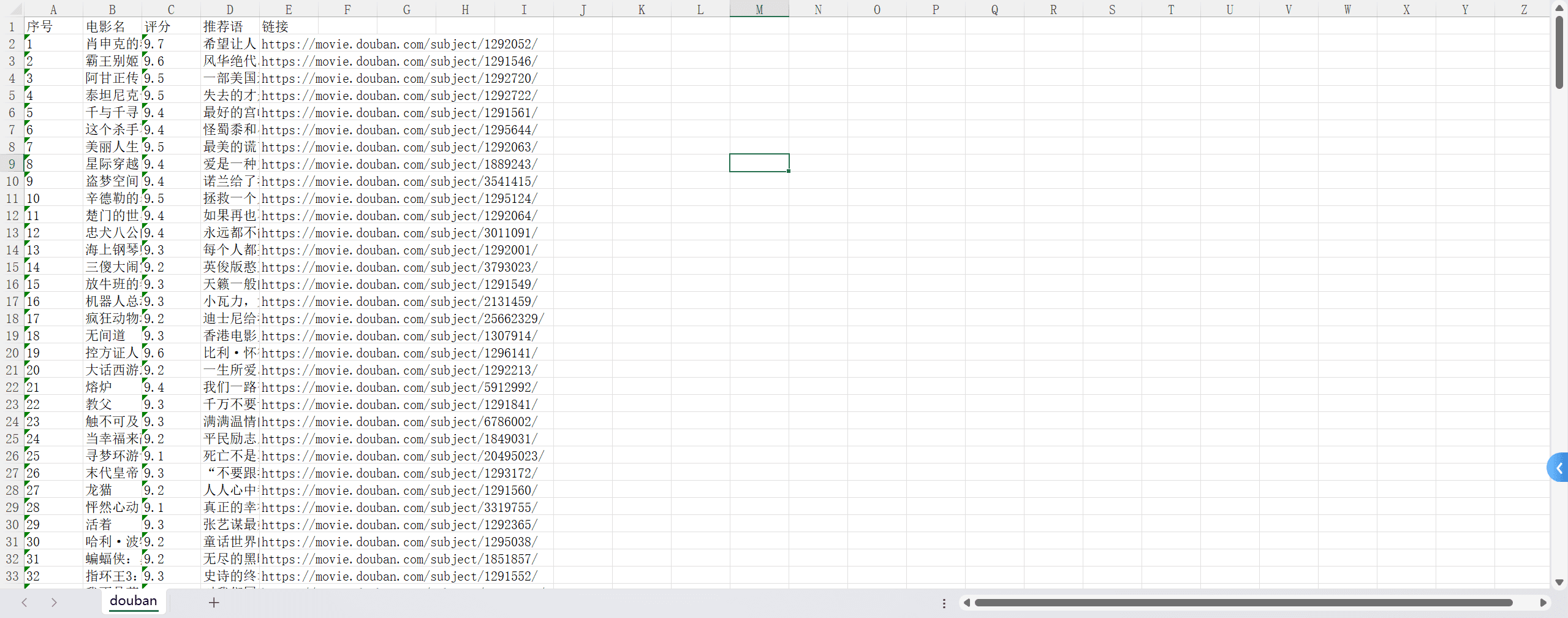
selenium
接下来我们讲解一下selenium,让浏览器自己动起来
安装selenium
控制台输入pip install selenium
安装chrome驱动
首先要确认你的chrome版本,打开chrome浏览器,然后输入chrome://version/查看版本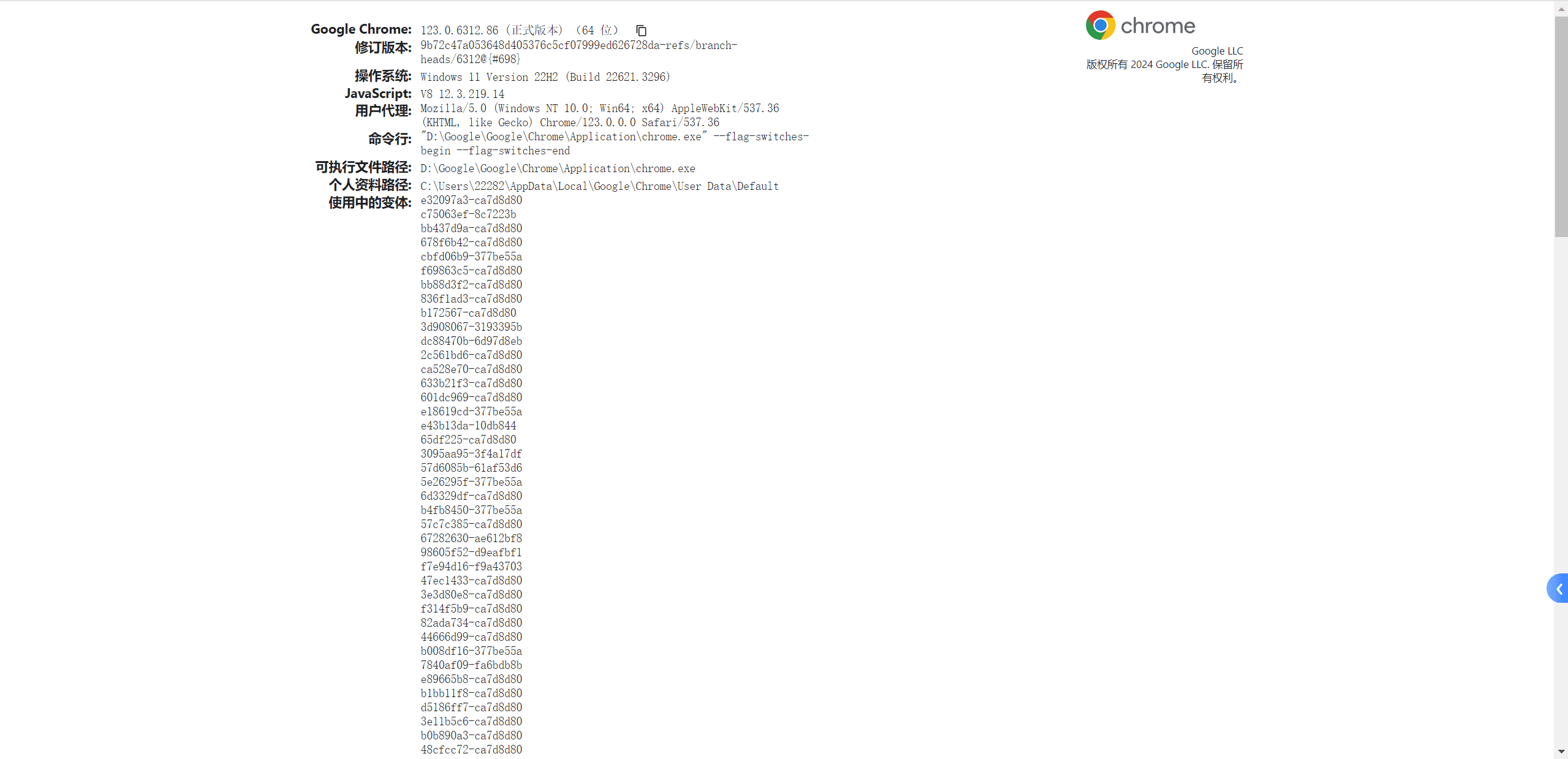
然后根据你的版本去下载驱动
https://chromedriver.com/download#stable
然后将驱动解压后的exe放到和python一个目录下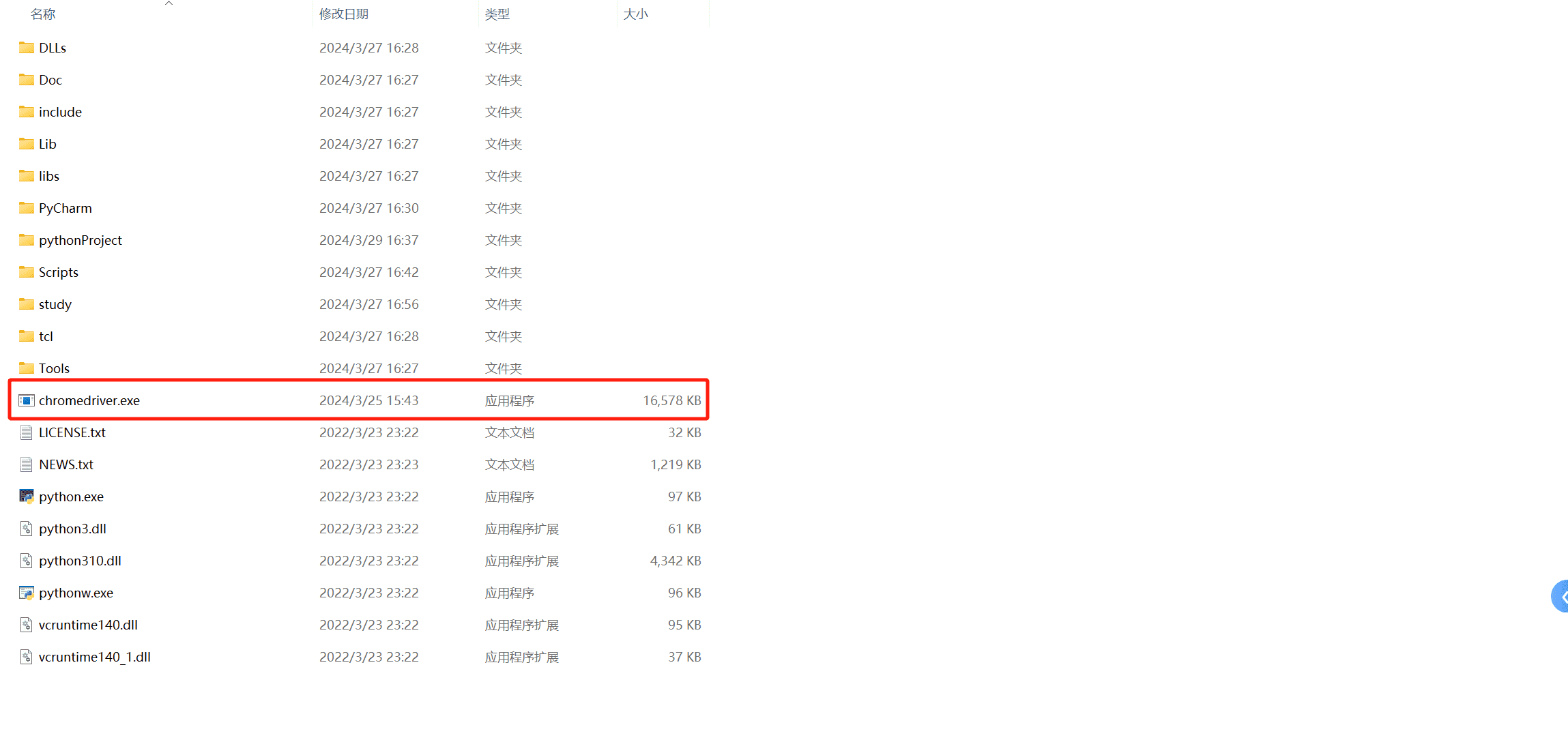
如果启动有问题就把驱动和谷歌浏览器的地址放到环境变量中
就类似于这样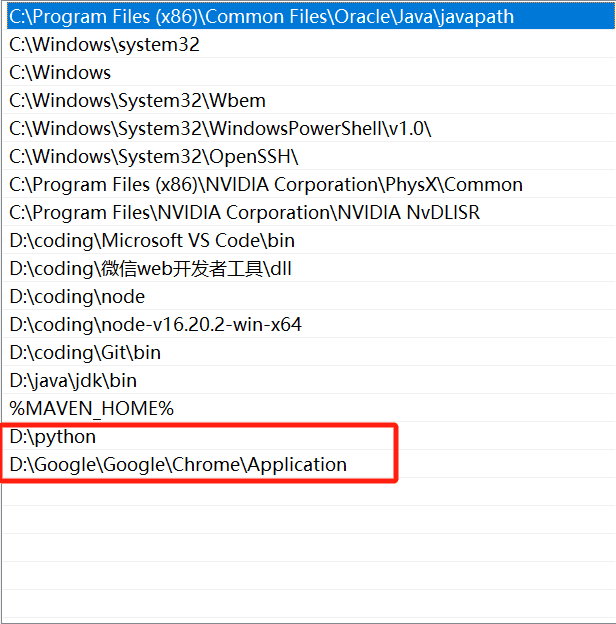
使用selenium
之后,我们就可以使用selenium了
1 | import time |
此时我们的代码可以帮我们自动打开百度网页,一秒后关闭网页
selenium获取数据
这里给大家一张图即可
此时我们获取出来的数据是WebElement类对象,这个我们之前的Tag类对象很像,你可以一起理解,这是他的属性
当然我们用selenium也可以批量获取dom,只需要将element变成elements即可
获取源代码
我们可以用page_source获取完整渲染的网页源代码
1 | driver = webdriver.Chrome() # 设置引擎为Chrome,真实地打开一个Chrome浏览器 |

selenium操作元素
这里我先简单贴张图片,后面我们会详细讲解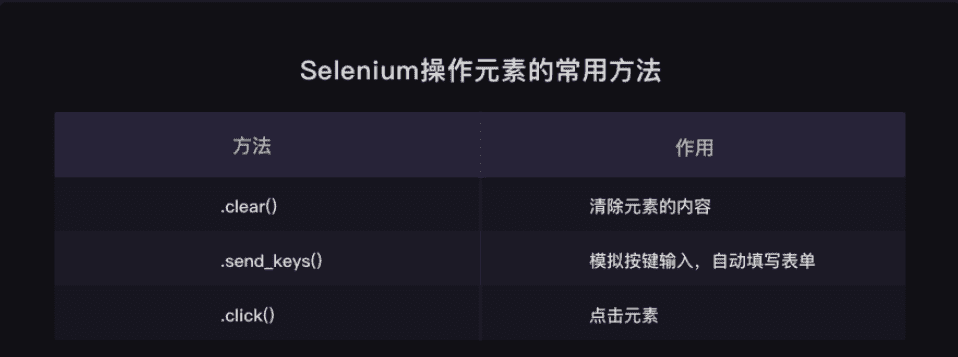
小练习
我们来做个小练习,自动打开百度,然后搜索codesigner,因为我的selenium比较新,所以获取元素的方式就改了,需要通过by来获取
1 | import time |
如果看这篇文章的有学生党,比如要刷做题次数的,那可就真的爽了,写个脚本,自动刷题。
定时与邮件
如何使用python发送邮件
首先,我们来了解一下python如何发送邮件,大概步骤如下:
需要使用到smtplib,email这两个模块。smtplib是用来发送邮件用的,email是用来构建邮件内容的。这两个都是Python内置模块。
开启邮箱服务
这里我以QQ邮箱为例,首先我们需要开启邮箱服务,然后获取授权码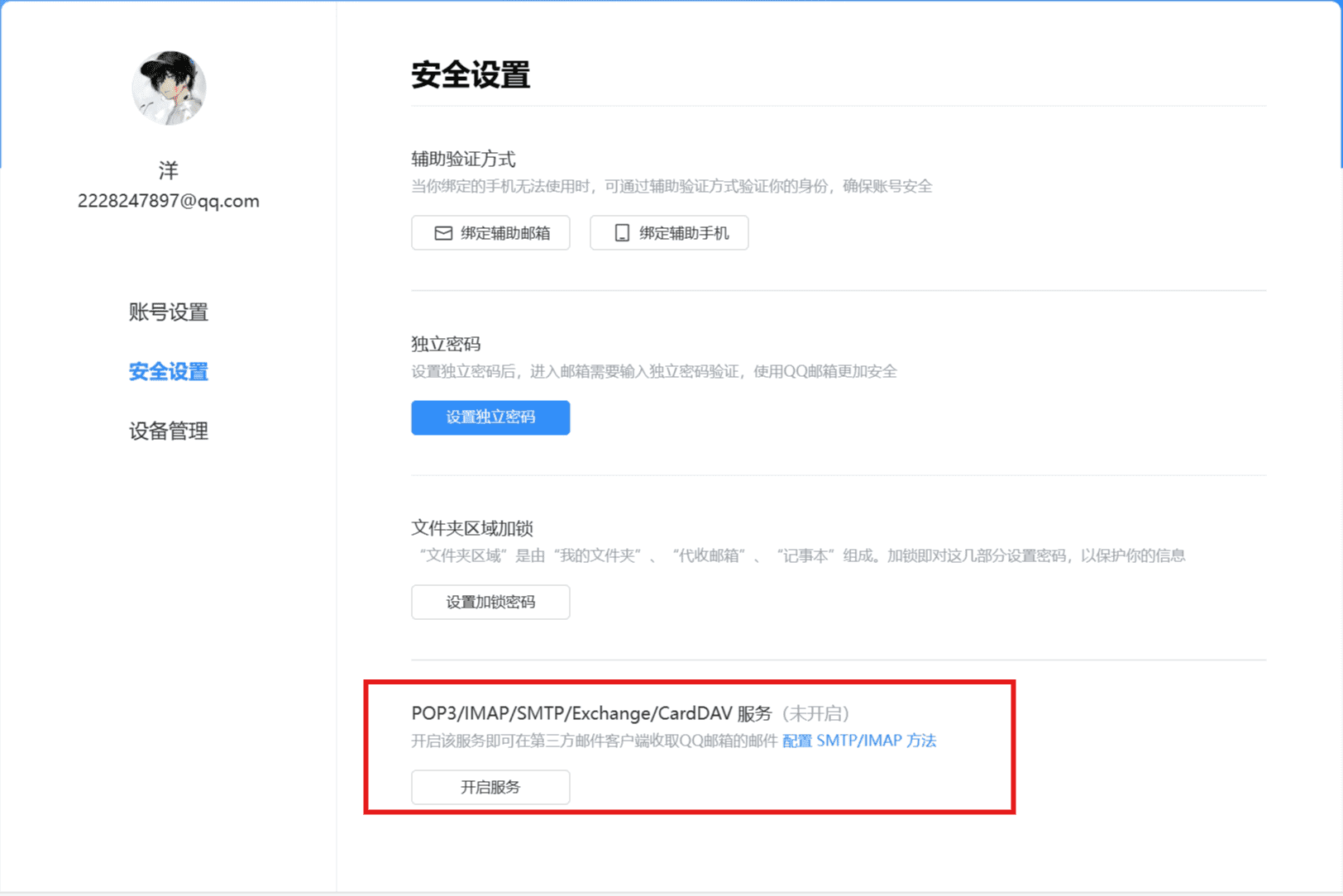
发送邮件
然后编写以下代码,内容我都有注释是啥意思了,大家可以自己尝试一下
1 | # smtplib 用于邮件的发信动作 |
然后,我们就可以收到邮件了
定时任务
首先要安装schedule
1 | pip install schedule |
然后我们可以使用schedule来做定时任务
1 | import schedule |
以此为基础,我们就可以使用爬虫,一定时间去爬取数据,然后发送邮件给我们自己或者将数据存入数据库等等操作
协程
我们已经做过不少爬虫项目,不过我们爬取的数据都不算太大,如果我们想要爬取的是成千上万条的数据,那么就会遇到一个问题:因为程序是一行一行依次执行的缘故,要等待很久,我们才能拿到想要的数据。
既然一个爬虫爬取大量数据要爬很久,那我们能不能让多个爬虫一起爬取?没错,这个就是协程
协程与非协程速率比较
这里举个简单的案例来说明协程的优势
没有协程
1 | import requests,time |
这时候的时间是1.281087875366211秒
使用协程
首先先安装gevent
1 | pip install gevent |
然后代码改成如下
1 | from gevent import monkey |
此时的时间是0.7206084728240967秒,这几个网站的访问就快了不少,这就是协程的优势
队列的使用
到这里,用gevent实操抓取6个网站我们已经完成,gevent的基础语法我们也大致了解。
那如果我们要爬的不是6个网站,而是1000个网站,我们可以怎么做?
用我们刚刚学的gevent语法,我们可以用gevent.spawn()创建1000个爬取任务,再用gevent.joinall()执行这1000个任务。
但这种方法会有问题:执行1000个任务,就是一下子发起1000次请求,这样子的恶意请求,会拖垮网站的服务器。
既然这种直接创建1000个任务的方式不可取,那我们能不能只创建成5个任务,但每个任务爬取200个网站?
遗憾地告诉你,这么做也还是会有问题的。就算我们用gevent.spawn()创建了5个分别执行爬取200个网站的任务,这5个任务之间是异步执行的,但是每个任务(爬取200个网站)内部是同步的。
这意味着:如果有一个任务在执行的过程中,它要爬取的一个网站一直在等待响应,哪怕其他任务都完成了200个网站的爬取,它也还是不能完成200个网站的爬取。
这个方法也不行,那还有什么方法呢?
这时我们可以从实际生活的案例中得到启发。想想银行是怎么在一天内办理1000个客户的业务的。
银行会开设办理业务的多个窗口,让客户取号排队,由银行的叫号系统分配客户到不同的窗口去办理业务。
在gevent库中,也有一个模块可以实现这种功能——queue模块。
当我们用多协程来爬虫,需要创建大量任务时,我们可以借助queue模块。
queue翻译成中文是队列的意思。我们可以用queue模块来存储任务,让任务都变成一条整齐的队列,就像银行窗口的排号做法。因为queue其实是一种有序的数据结构,可以用来存取数据。
这样,协程就可以从队列里把任务提取出来执行,直到队列空了,任务也就处理完了。就像银行窗口的工作人员会根据排号系统里的排号,处理客人的业务,如果已经没有新的排号,就意味着客户的业务都已办理完毕。
接下来,我们来实操看看,可以怎么用queue模块和协程配合,依旧以抓取6个网站为例。
导入模块
1 | from gevent import monkey |
如何创建队列,以及怎么把任务存储进队列里
1 | start = time.time() |
用Queue()能创建queue对象,相当于创建了一个不限任何存储数量的空队列。如果我们往Queue()中传入参数,比如Queue(10),则表示这个队列只能存储10个任务。
创建了queue对象后,我们就能调用这个对象的put_nowait方法,把我们的每个网址都存储进我们刚刚建立好的空队列里。
work.put_nowait(url)这行代码就是把遍历的6个网站,都存储进队列里。
是定义爬取函数,和如何从队列里提取出刚刚存储进去的网址
1 | def crawler(): |
这里定义的crawler函数,多了三个你可能看不懂的代码:1.while not work.empty():;2.url = work.get_nowait();3.work.qsize()。
这三个代码涉及到queue对象的三个方法:empty方法,是用来判断队列是不是空了的;get_nowait方法,是用来从队列里提取数据的;qsize方法,是用来判断队列里还剩多少数量的。
当然,queue对象的方法还不止这几种,比如有判断队列是否为空的empty方法,对应也有判断队列是否为满的full方法。
你是不是觉得queue对象这么多方法,一下子记不住?其实,这些不需要你死记硬背的,附上一张queue对象的方法表,你只需要在用到的时候,查查表就好。
爬取队列
上面这个3部分,我们讲解完了。如果你能明白队列怎么创建、数据怎么存储进队列,以及怎么从队列里提取出的数据,就说明queue模块的重点内容你都掌握了。
接在3部分代码的后面,就是让爬虫用多协程执行任务,爬取队列里的6个网站的代码(重点看有注释的代码)。
1 | def crawler(): |
完整代码如下
1 | from gevent import monkey |
练习
ok,学到这里,我们做个练习,巩固一下我们的知识
我最近不是也在减肥吗?刚好有个热量的网站,我就来爬取一下它的数据。
网址:https://www.boohee.com/food
需求整理分析
简单浏览一下这个网站,你会发现一共有11个常见食物分类——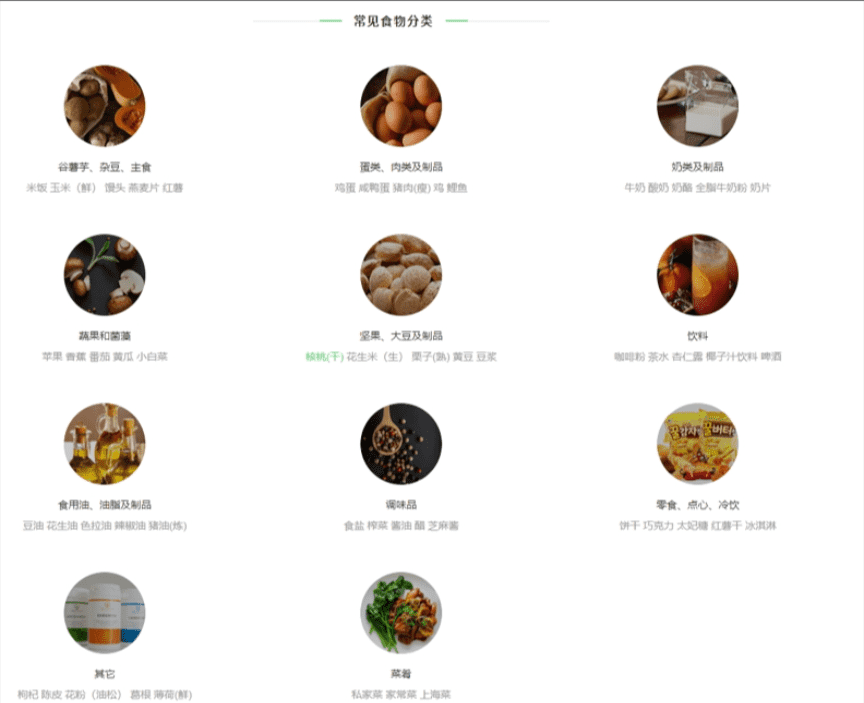
点击【谷薯芋、杂豆、主食】这个分类,你会看到在食物分类的右边,有10页食物的记录,包含了这个分类里食物的名字,及其热量信息。点击食物的名字还会跳转到食物的详情页面。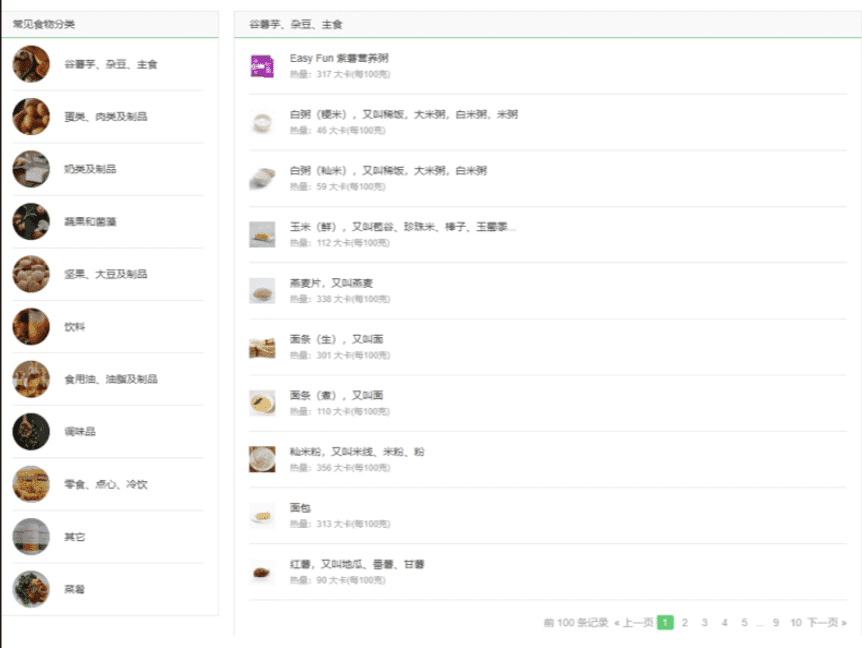
至此,我们的项目目标可以定为:用多协程爬取薄荷网11个常见食物分类里的食物信息(包含食物名、热量、食物详情页面链接)
目标明确好后,我们接着【分析过程】,这一步骤对于项目成功与否起着关键的作用。
我们可以从爬虫四步(获取数据→解析数据→提取数据→存储数据)入手,开始逐一分析。
想要获得食物热量的数据,我们得先判断这些数据具体存在哪里。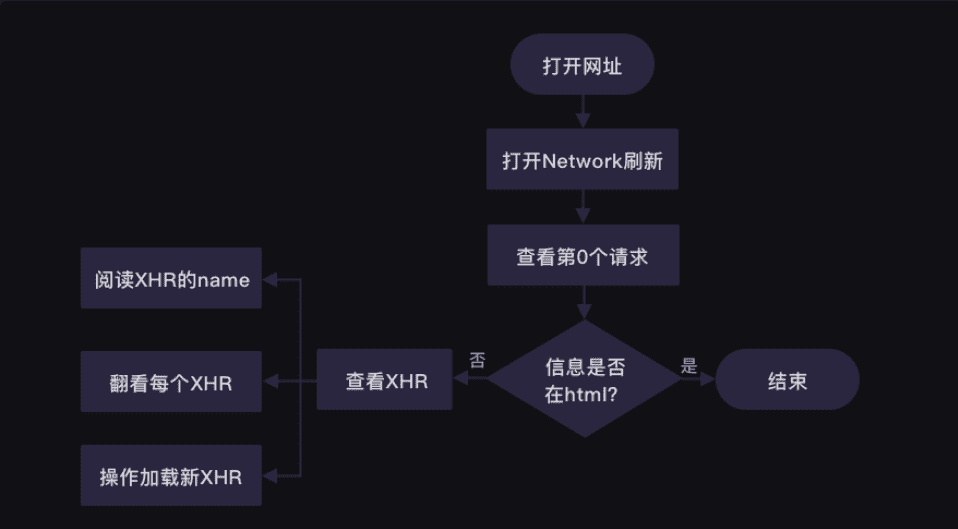
而这个网站,数据是存在html中的
点击第一个分类【谷薯芋、杂豆、主食】,网址显示的是:
http://www.boohee.com/food/group/1
点击第二个分类【蛋类、肉类及制品】,网址变成:
http://www.boohee.com/food/group/2
我们可以做个猜想:网址的group参数代表着常见食物分类,后面的数字代表着这是第几个类。
只要再多点击几个常见食物分类看看,就能验证我们的猜想。

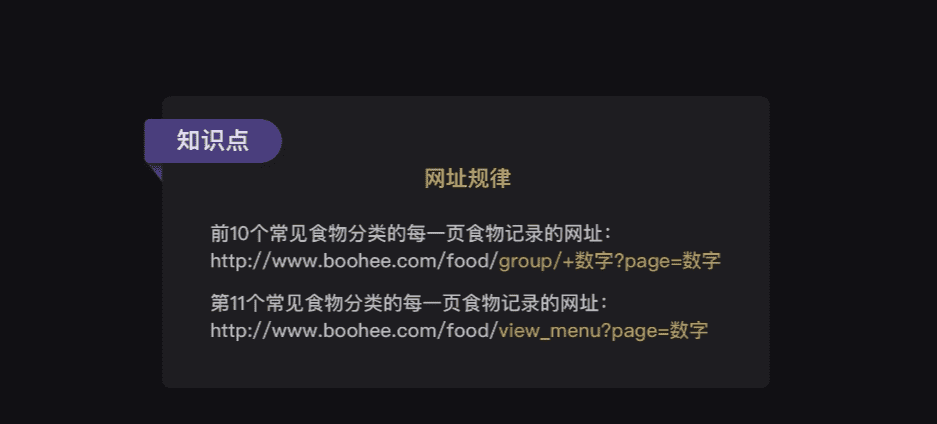
果然,常见食物分类的网址构造是有规律的。前10个常见食物分类的网址都是:
http://www.boohee.com/food/group/+数字
唯独最后一个常见食物分类【菜肴】的网址与其他不同,是:
http://www.boohee.com/food/view_menu
每个常见食物分类网址的规律我们找到了。现在看回【谷薯芋、杂豆、主食】这个分类,点击翻到第2页的食物记录,我们看看网址又会发生怎样的变化。
网址从http://www.boohee.com/food/group/1变成了:
http://www.boohee.com/food/group/1?page=2
网址多了page这个参数。数字2是不是第2页的意思?我们往后再翻两页看看。
原来?page=数字真的是代表页数的意思。只要改变page后面的数字,就能实现翻页。
可是为什么第1页的食物记录的网址在最开始是:
http://www.boohee.com/food/group/1,没有加?page=1呢?
难道是网站默认不显示的?我们试下给http://www.boohee.com/food/group/1加上?page=1,看看会怎样。
http://www.boohee.com/food/group/1?page=1
你会发现,其实加上了?page=1,打开的同样还是第1页的食物记录。
基于我们上面的观察,可以得出薄荷网每个食物类别的每一页食物记录的网址规律——
接下来,我们来分析怎么解析数据和提取数据。
前面我们知道薄荷网的食物热量的数据都存在HTML里,所以等下就可以用BeautifulSoup模块来解析。
至于怎么提取数据,我们得先弄清楚HTML的结构才行。他的结构也非常清除,就是一个个li标签,里面包含了食物的名字,热量,详情页链接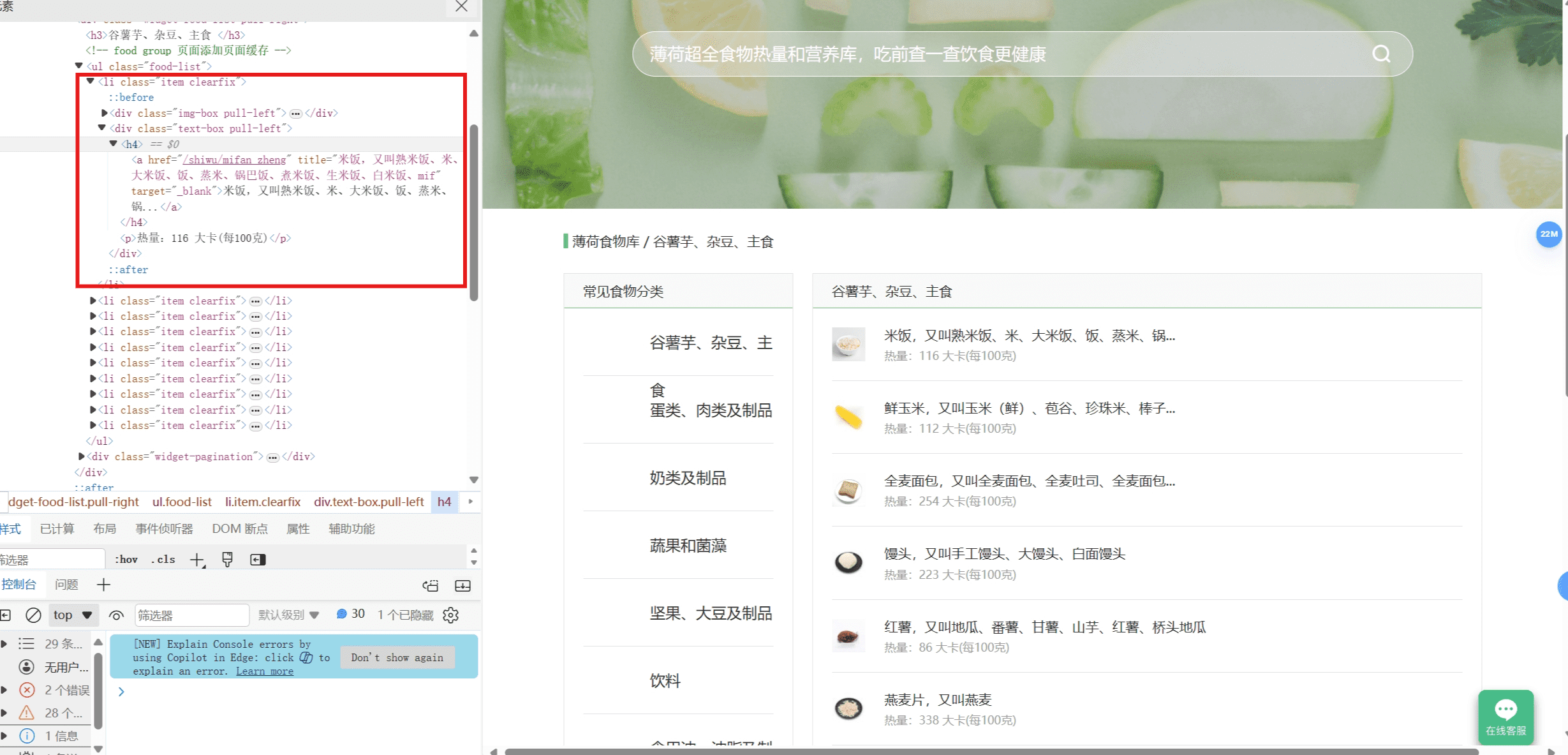
编写代码
到这里,我们就可以来编写代码了
- 导入库和模块写代码的第一件事,都是先导入我们所需要的库和模块。
1
2
3
4
5
6#导入所需的库和模块:
from gevent import monkey
monkey.patch_all()
#让程序变成异步模式。
import gevent,requests, bs4, csv
from gevent.queue import Queue
根据项目目标和分析过程得出的思路,我们知道需要用到实现协程功能的gevent库、queue、monkey模块,以及requests、BeautifulSoup、csv模块。
创建队列
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22work = Queue()
#创建队列对象,并赋值给work。
#前3个常见食物分类的前3页的食物记录的网址:
url_1 = 'http://www.boohee.com/food/group/{type}?page={page}'
for x in range(1, 4):
for y in range(1, 4):
real_url = url_1.format(type=x, page=y)
work.put_nowait(real_url)
#通过两个for循环,能设置分类的数字和页数的数字。
#然后,把构造好的网址用put_nowait方法添加进队列里。
#第11个常见食物分类的前3页的食物记录的网址:
url_2 = 'http://www.boohee.com/food/view_menu?page={page}'
for x in range(1,4):
real_url = url_2.format(page=x)
work.put_nowait(real_url)
#通过for循环,能设置第11个常见食物分类的食物的页数。
#然后,把构造好的网址用put_nowait方法添加进队列里。
print(work)
#打印队列定义爬取函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26def crawler():
#定义crawler函数
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'
}
#添加请求头
while not work.empty():
#当队列不是空的时候,就执行下面的程序。
url = work.get_nowait()
#用get_nowait()方法从队列里把刚刚放入的网址提取出来。
res = requests.get(url, headers=headers)
#用requests.get获取网页源代码。
bs_res = bs4.BeautifulSoup(res.text, 'html.parser')
#用BeautifulSoup解析网页源代码。
foods = bs_res.find_all('li', class_='item clearfix')
#用find_all提取出<li class="item clearfix">标签的内容。
for food in foods:
#遍历foods
food_name = food.find_all('a')[1]['title']
#用find_all在<li class="item clearfix">标签下,提取出第2个<a>元素title属性的值,也就是食物名称。
food_url = 'http://www.boohee.com' + food.find_all('a')[1]['href']
#用find_all在<li class="item clearfix">元素下,提取出第2个<a>元素href属性的值,跟'http://www.boohee.com'组合在一起,就是食物详情页的链接。
food_calorie = food.find('p').text
#用find在<li class="item clearfix">标签下,提取<p>元素,再用text方法留下纯文本,也提取出了食物的热量。
print(food_name)
#打印食物的名称。创建执行任务
1
2
3
4
5
6
7
8
9
10tasks_list = []
#创建空的任务列表
for x in range(5):
#相当于创建了5个爬虫
task = gevent.spawn(crawler)
#用gevent.spawn()函数创建执行crawler()函数的任务。
tasks_list.append(task)
#往任务列表添加任务。
gevent.joinall(tasks_list)
#用gevent.joinall方法,启动协程,执行任务列表里的所有任务,让爬虫开始爬取网站。存储数据
1
2
3
4
5
6csv_file= open('boohee.csv', 'w', newline='')
#调用open()函数打开csv文件,传入参数:文件名“boohee.csv”、写入模式“w”、newline=''。
writer = csv.writer(csv_file)
# 用csv.writer()函数创建一个writer对象。
writer.writerow(['食物', '热量', '链接'])
#借助writerow()函数往csv文件里写入文字:食物、热量、链接此时我们的完整代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51from gevent import monkey
monkey.patch_all()
import gevent,requests, bs4, csv
from gevent.queue import Queue
def get_txt():
work = Queue()
url_1 = 'http://www.boohee.com/food/group/{type}?page={page}'
for x in range(1, 4):
for y in range(1, 4):
real_url = url_1.format(type=x, page=y)
work.put_nowait(real_url)
url_2 = 'http://www.boohee.com/food/view_menu?page={page}'
for x in range(1, 4):
real_url = url_2.format(page=x)
work.put_nowait(real_url)
def crawler():
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'
}
while not work.empty():
url = work.get_nowait()
res = requests.get(url, headers=headers)
bs_res = bs4.BeautifulSoup(res.text, 'html.parser')
foods = bs_res.find_all('li', class_='item clearfix')
for food in foods:
food_name = food.find_all('a')[1]['title']
food_url = 'http://www.boohee.com' + food.find_all('a')[1]['href']
food_calorie = food.find('p').text
writer.writerow([food_name, food_calorie, food_url])
# 借助writerow()函数,把提取到的数据:食物名称、食物热量、食物详情链接,写入csv文件。
print(food_name)
csv_file = open('boohee.csv', 'w', newline='')
# 调用open()函数打开csv文件,传入参数:文件名“boohee.csv”、写入模式“w”、newline=''。
writer = csv.writer(csv_file)
# 用csv.writer()函数创建一个writer对象。
writer.writerow(['食物', '热量', '链接'])
# 借助writerow()函数往csv文件里写入文字:食物、热量、链接
tasks_list = []
for x in range(5):
task = gevent.spawn(crawler)
tasks_list.append(task)
gevent.joinall(tasks_list)
# Press the green button in the gutter to run the script.
if __name__ == '__main__':
get_txt()
执行完成之后,我们就可以看到我们的csv文件了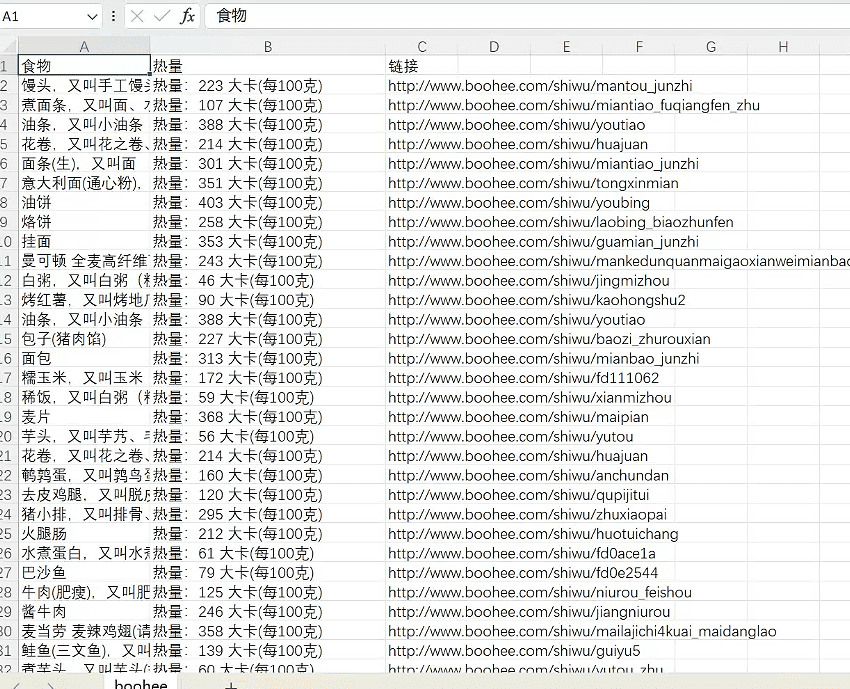
Scrapy框架
以前我们写爬虫,要导入和操作不同的模块,比如requests模块、gevent库、csv模块等。而在Scrapy里,你不需要这么做,因为很多爬虫需要涉及的功能,比如麻烦的异步,在Scrapy框架都自动实现了。
我们之前编写爬虫的方式,相当于在一个个地在拼零件,拼成一辆能跑的车。而Scrapy框架则是已经造好的、现成的车,我们只要踩下它的油门,它就能跑起来。这样便节省了我们开发项目的时间。
下面,我们来了解Scrapy的基础知识,包括Scrapy的结构及其工作原理。
Scrapy的结构
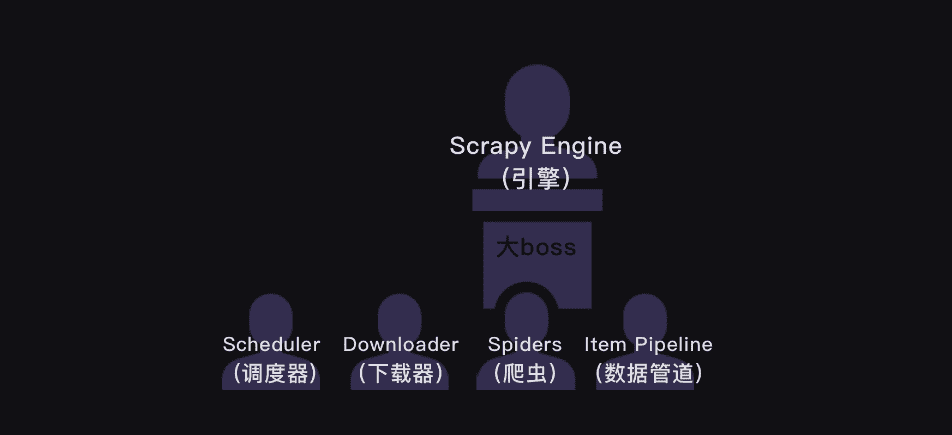
上面的这张图是Scrapy的整个结构。你可以把整个Scrapy框架看成是一家爬虫公司。最中心位置的Scrapy Engine(引擎)就是这家爬虫公司的大boss,负责统筹公司的4大部门,每个部门都只听从它的命令,并只向它汇报工作。
我会以爬虫流程的顺序来依次跟你介绍Scrapy爬虫公司的4大部门。
Scheduler(调度器)部门主要负责处理引擎发送过来的requests对象(即网页请求的相关信息集合,包括params,data,cookies,request headers…等),会把请求的url以有序的方式排列成队,并等待引擎来提取(功能上类似于gevent库的queue模块)。
Downloader(下载器)部门则是负责处理引擎发送过来的requests,进行网页爬取,并将返回的response(爬取到的内容)交给引擎。它对应的是爬虫流程【获取数据】这一步。
Spiders(爬虫)部门是公司的核心业务部门,主要任务是创建requests对象和接受引擎发送过来的response(Downloader部门爬取到的内容),从中解析并提取出有用的数据。它对应的是爬虫流程【解析数据】和【提取数据】这两步。
Item Pipeline(数据管道)部门则是公司的数据部门,只负责存储和处理Spiders部门提取到的有用数据。这个对应的是爬虫流程【存储数据】这一步。
Downloader Middlewares(下载中间件)的工作相当于下载器部门的秘书,比如会提前对引擎大boss发送的诸多requests做出处理。
Spider Middlewares(爬虫中间件)的工作则相当于爬虫部门的秘书,比如会提前接收并处理引擎大boss发送来的response,过滤掉一些重复无用的东西。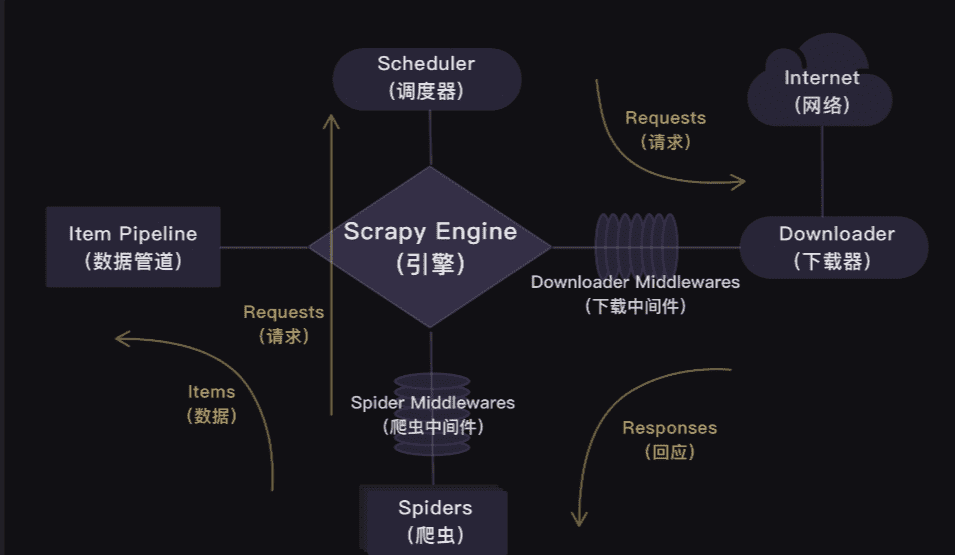
Scrapy的工作原理
你会发现,在Scrapy爬虫公司里,每个部门都各司其职,形成了很高效的运行流程。
这套运行流程的逻辑很简单,就是:引擎大boss说的话就是最高需求。
在Scrapy里,整个爬虫程序的流程都不需要我们去操心,且Scrapy中的程序全部都是异步模式,所有的请求或返回的响应都由引擎自动分配去处理。
哪怕有某个请求出现异常,程序也会做异常处理,跳过报错的请求,继续往下运行程序。
在一定程度上,Scrapy可以说是非常让人省心的一套爬虫框架。
Scrapy的用法
现在,你已经初步了解Scrapy的结构以及工作原理。接下来,为了让你熟悉Scrapy的用法,我们使用它来完成一个小练习,还是之前的豆瓣网的电影信息
安装Scrapy
首先还是要先进行安装
1 | pip install scrapy |
创建Scrapy项目
找个目录的终端创建项目
1 | scrapy startproject douban |
创建完成之后,目录结构如下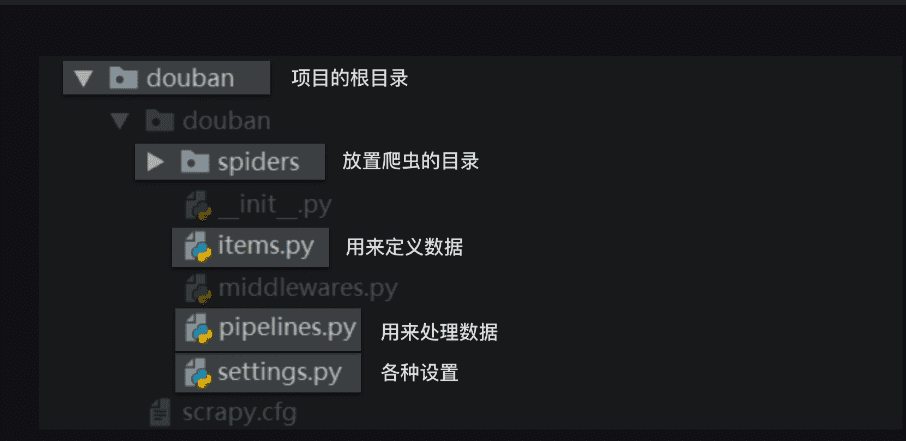
Scrapy项目里每个文件都有特定的功能,比如settings.py 是scrapy里的各种设置。items.py是用来定义数据的,pipelines.py是用来处理数据的,它们对应的就是Scrapy的结构中的Item Pipeline(数据管道)。
现在或许你还看不懂它们,没关系,事情将会一点点变清晰。我们来讲解它们。
编写爬虫
代码实现——编辑爬虫
如前所述,spiders是放置爬虫的目录。我们可以在spiders这个文件夹里创建爬虫文件。我们来把这个文件,命名为top250。后面的大部分代码都需要在这个top250.py文件里编写。
先在top250.py文件里导入我们需要的模块。
1 | import scrapy |
导入BeautifulSoup用于解析和提取数据,这个应该不需要我多做解释。在第2关、第3关的时候你就已经对它非常熟稔。
导入scrapy是待会我们要用创建类的方式写这个爬虫,我们所创建的类将直接继承scrapy中的scrapy.Spider类。这样,有许多好用属性和方法,就能够直接使用。
接着我们开始编写爬虫的核心代码。
在Scrapy中,每个爬虫的代码结构基本都如下所示:
1 | class DoubanSpider(scrapy.Spider): |
第1行代码:定义一个爬虫类DoubanSpider。就像我刚刚讲过的那样,DoubanSpider类继承自scrapy.Spider类。
第2行代码:name是定义爬虫的名字,这个名字是爬虫的唯一标识。name = ‘douban’意思是定义爬虫的名字为douban。等会我们启动爬虫的时候,要用到这个名字。
第3行代码:allowed_domains是定义允许爬虫爬取的网址域名(不需要加https://)。如果网址的域名不在这个列表里,就会被过滤掉。
为什么会有这个设置呢?当你在爬取大量数据时,经常是从一个URL开始爬取,然后关联爬取更多的网页。比如,假设我们今天的爬虫目标不是爬书籍信息,而是要爬豆瓣图书top250的书评。我们会先爬取书单,再找到每本书的URL,再进入每本书的详情页面去抓取评论。
allowed_domains就限制了,我们这种关联爬取的URL,一定在book.douban.com这个域名之下,不会跳转到某个奇怪的广告页面。
第4行代码:start_urls是定义起始网址,就是爬虫从哪个网址开始抓取。在此,allowed_domains的设定对start_urls里的网址不会有影响。
第6行代码:parse是Scrapy里默认处理response的一个方法,中文是解析。
你或许会好奇,这里是不是少了一句类似requests.get()这样的代码?的确是,在这里,我们并不需要写这一句。scrapy框架会为我们代劳做这件事,写好你的请求,接下来你就可以直接写对响应如何做处理,我会在后面为你做示例。
然后我们写个循环,把所有的电影地址都给加入到start_urls里
1 | start_urls = [] |
接下来,只要再借助parse方法处理response,借助BeautifulSoup来取出我们想要的书籍信息的数据,代码即可完成。参考之前做的
1 | def parse(self, response): |
按照过去,我们会把名称、评分等分别赋值,然后统一做处理——或是打印,或是存储。但在scrapy这里,事情却有所不同。
spiders(如top250.py)只干spiders应该做的事。对数据的后续处理,另有人负责。
定义数据
在scrapy中,我们会专门定义一个用于记录数据的类。
当我们每一次,要记录数据的时候,比如前面在每一个最小循环里,都要记录“书名”,“出版信息”,“评分”。我们会实例化一个对象,利用这个对象来记录数据。
每一次,当数据完成记录,它会离开spiders,来到Scrapy Engine(引擎),引擎将它送入Item Pipeline(数据管道)处理。
定义这个类的py文件,正是items.py。
我们已经知道,我们要爬取的数据是电影名称,推荐语,链接,序号,和评分,我们来看看如何在items.py里定义这些数据。代码如下:
1 | import scrapy |
scrapy.Field()这行代码实现的是,让数据能以类似字典的形式记录。
赋值处理
在top250.py里,我们需要把数据赋值给DoubanItem类,然后再交给Scrapy Engine(引擎)。
1 | import scrapy |
每一次,当数据完成记录,它会离开spiders,来到Scrapy Engine(引擎),引擎将它送入Item Pipeline(数据管道)处理。这里,要用到yield语句。
yield语句你可能还不太了解,这里你可以简单理解为:它有点类似return,不过它和return不同的点在于,它不会结束函数,且能多次返回信息。
具体而言就是爬虫(Spiders)会把豆瓣的10个网址封装成requests对象,引擎会从爬虫(Spiders)里提取出requests对象,再交给调度器(Scheduler),让调度器把这些requests对象排序处理。
然后引擎再把经过调度器处理的requests对象发给下载器(Downloader),下载器会立马按照引擎的命令爬取,并把response返回给引擎。
紧接着引擎就会把response发回给爬虫(Spiders),这时爬虫会启动默认的处理response的parse方法,解析和提取出书籍信息的数据,使用item做记录,返回给引擎。引擎将它送入Item Pipeline(数据管道)处理。
设置
到这里,我们就用代码编写好了一个爬虫。不过,实际运行的话,可能还是会报错。
原因在于Scrapy里的默认设置没被修改。比如我们需要修改请求头。点击settings.py文件,你能在里面找到如下的默认设置代码:
1 | # Crawl responsibly by identifying yourself (and your website) on the user-agent |
把USER _AGENT的注释取消(删除#),然后替换掉user-agent的内容,就是修改了请求头。
又因为Scrapy是遵守robots协议的,如果是robots协议禁止爬取的内容,Scrapy也会默认不去爬取,所以我们还得修改Scrapy中的默认设置。
把ROBOTSTXT_OBEY=True改成ROBOTSTXT_OBEY=False,就是把遵守robots协议换成无需遵从robots协议,这样Scrapy就能不受限制地运行。
修改后的代码应该如下所示:
1 | # Crawl responsibly by identifying yourself (and your website) on the user-agent |
运行
方式一
想要运行Scrapy有两种方法,一种是在本地电脑的终端跳转到scrapy项目的文件夹(跳转方法:cd+文件夹的路径名),然后输入命令行:scrapy crawl douban(douban 就是我们爬虫的名字)。
方式二
另一种运行方式需要我们在最外层的大文件夹里新建一个main.py文件(与scrapy.cfg同级)。在main.py文件里写入如下代码:
1 | from scrapy import cmdline |
第1行代码:在Scrapy中有一个可以控制终端命令的模块cmdline。导入了这个模块,我们就能操控终端。
第3行代码:在cmdline模块中,有一个execute方法能执行终端的命令行,不过这个方法需要传入列表的参数。我们想输入运行Scrapy的代码scrapy crawl douban,就需要写成[‘scrapy’,’crawl’,’douban’]这样。
至此,Scrapy的用法我们学完啦。
再追加一点,我们可以把数据存储到csv中,这里我就简单讲解一下例子
其实,在Scrapy里,把数据存储成csv文件和Excel文件,也有分别对应的方法。我们先说csv文件。
存储成csv文件的方法比较简单,只需在settings.py文件里,添加如下的代码即可。
1 | FEED_URI='./storage/data/%(name)s.csv' |
FEED_URI是导出文件的路径。’./storage/data/%(name)s.csv’,就是把存储的文件放到与main.py文件同级的storage文件夹的data子文件夹里。
FEED_FORMAT 是导出数据格式,写CSV就能得到CSV格式。
FEED_EXPORT_ENCODING 是导出文件编码,ansi是一种在windows上的编码格式,你也可以把它变成utf-8用在mac电脑上。
存储成Excel文件的方法要稍微复杂一些,我们需要先在settings.py里设置启用ITEM_PIPELINES,设置方法如下:
1 | #需要修改`ITEM_PIPELINES`的设置代码: |
只要取消ITEM_PIPELINES的注释(删掉#)即可。
接着,我们就可以去编辑pipelines.py文件。存储为Excel文件,我们依旧是用openpyxl模块来实现,代码如下,注意阅读注释:
1 | import openpyxl |
再补充一点如何网站爬取不宜过快可以加上爬虫延迟,在settings.py文件里,找到DOWNLOAD_DELAY这行代码:
1 | # Configure a delay for requests for the same website (default: 0) |
我们需要取消DOWNLOAD_DELAY = 0这行的注释(删掉#)。DOWNLOAD_DELAY翻译成中文是下载延迟的意思,这行代码可以控制爬虫的速度。因为这个项目的爬取速度不宜过快,我们要把下载延迟的时间改成0.5秒。
结语
到这里,本篇文章就该结束了,如果大家有跟着我一起学习下来,相信已经学会了基本的爬虫技巧了吧。至此,我的python复习也就告一段落了,债见,祝大家清明节休息愉快!



