前言
本篇来学习一下sql的常用函数
本篇学习目标
sql常用函数
avg
定义
AVG() 函数返回数值列的平均值。
使用
为了方便测试,我新建了一个带有数字的表,结构如下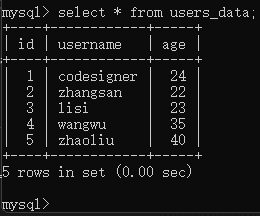
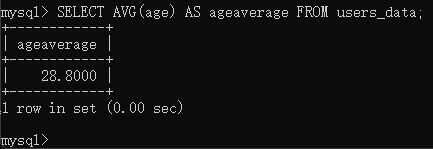
ok,接下来我们使用avg函数,求一下这个表中的age的平均值
1 | SELECT AVG(age) AS ageaverage FROM users_data; |
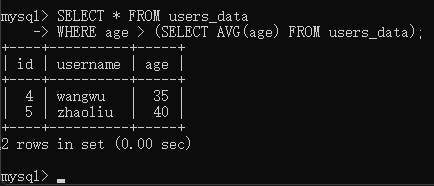
当然我们也可以求年龄大于平均值的数据
1 | SELECT * FROM users_data |
count
定义
这个相当于统计符合条件的条数有几个
使用
我这里求一下年龄大于30岁以上的人有几个
1 | select count(age) as nums from users_data where age>30; |
答案显而易见就是2个。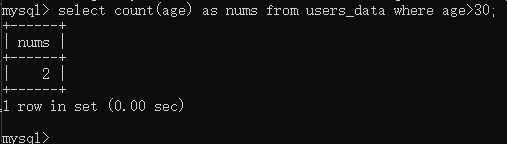
同理,我们可以计算总条数
1 | SELECT COUNT(*) AS nums FROM users_data; |
也可以计算去重后的条数
1 | SELECT COUNT(DISTINCT age) AS nums FROM users_data; |
first
定义
FIRST() 函数返回指定的列中第一个记录的值。
使用
1 | SELECT FIRST(column_name) FROM table_name; |
但是mysql中不支持这个函数,我们如果要实现相同的效果就需要这样来得到
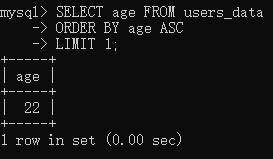
比如我们想要年龄最小的那个数据
1 | SELECT age FROM users_data |
last
定义
LAST() 函数返回指定的列中最后一个记录的值。
使用
1 | SELECT LAST(column_name) FROM table_name; |
同样的。mysql并不支持这个函数,我们如果要实现相同的效果就需要这样来得到
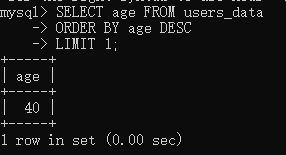
比如我们想要年龄最大的那个数据
1 | SELECT age FROM users_data |
max
定义
MAX() 函数返回指定列的最大值。
使用
同样的我们求年龄最大值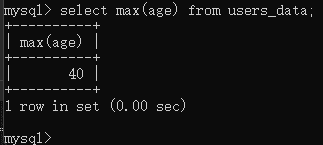
min
定义
MIN() 函数返回指定列的最小值。
使用
我们求年龄的最小值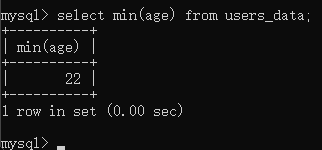
sum
定义
SUM() 函数返回数值列的总数
使用
比如我想要求年龄总和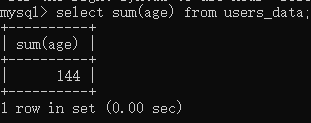
group by
定义
GROUP BY 语句可结合一些聚合函数来使用
group by简单使用
我这里再添加一个lisi的数据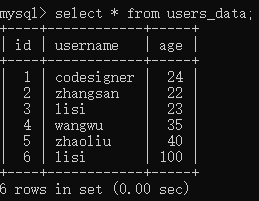
然后我统计各个名字对应的年龄是多少
1 | select id,username,sum(users_data.age) as nums from users_data group by username; |
我们可以看到,我根据username合并了数据,将俩lisi的年龄加了起来。
GROUP BY 多表连接
我有这样俩个表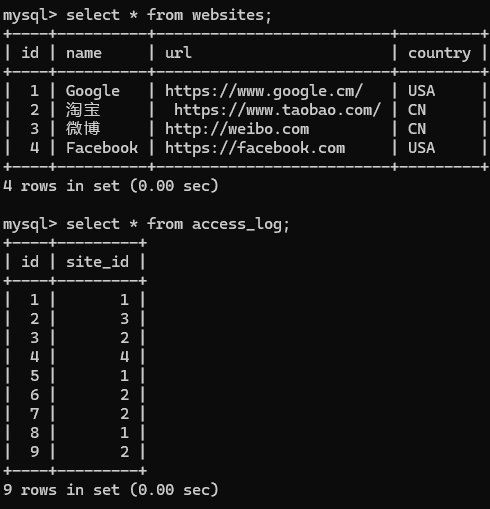
我将websites的id和access_log中的site_id出现1,2,3,4对应起来,求出现的次数,此时的代码如下
1 | SELECT websites.name,COUNT(access_log.id) AS nums FROM access_log |
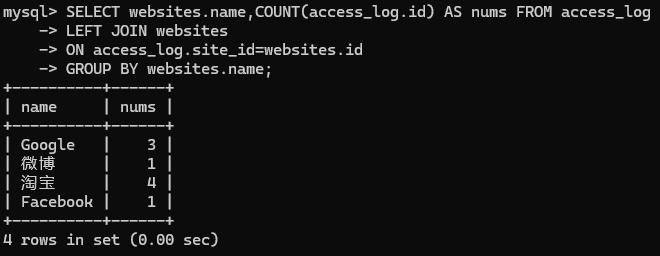
HAVING
定义
HAVING 子句
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与聚合函数一起使用。
HAVING 子句可以让我们筛选分组后的各组数据。
使用
1 | SELECT column1, aggregate_function(column2) |
column1:要检索的列。
aggregate_function(column2):一个聚合函数,例如SUM、COUNT、AVG等,应用于column2的值。
table_name:要从中检索数据的表。
GROUP BY column1:根据column1列的值对数据进行分组。
HAVING condition:一个条件,用于筛选分组的结果。只有满足条件的分组会包含在结果集中。
我新建了一个access_logs的表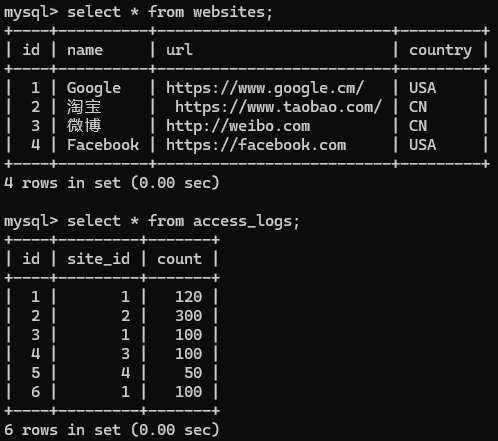
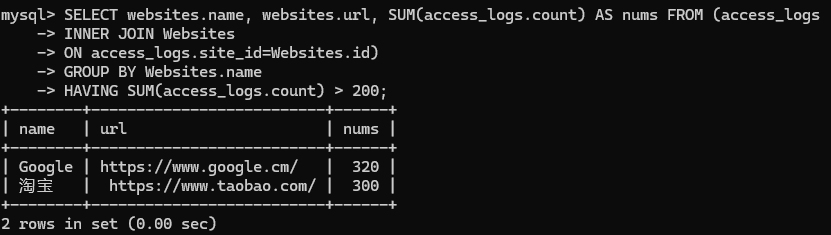
现在我们想要查找总访问量大于 200 的网站。
我们使用下面的 SQL 语句:
1 | SELECT websites.name, websites.url, SUM(access_logs.count) AS nums FROM (access_logs |
EXISTS
定义
EXISTS 运算符用于判断查询子句是否有记录,如果有一条或多条记录存在返回 True,否则返回 False。
使用
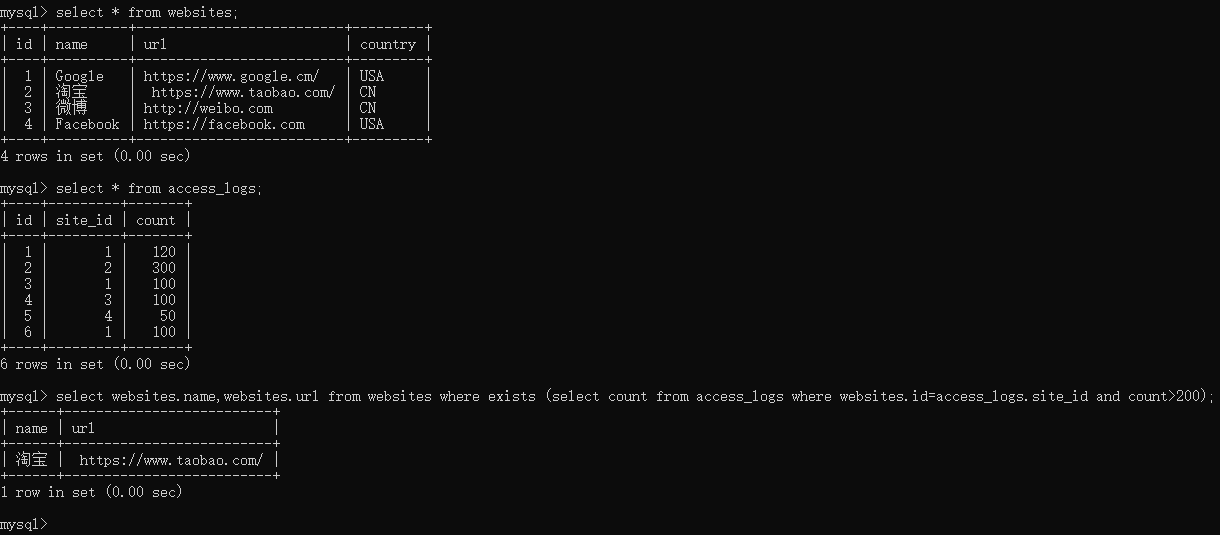
比如我们现在我们想要查找访问量(count 字段)大于 200 的网站是否存在。
1 | select websites.name,websites.url from websites where exists (select count from access_logs where websites.id=access_logs.site_id and count>200); |
UCASE
定义
UCASE() 函数把字段的值转换为大写。
使用
SQL UCASE() 语法
1 | SELECT UCASE(column_name) FROM table_name; |
用于 SQL Server 的语法
1 | SELECT UPPER(column_name) FROM table_name; |
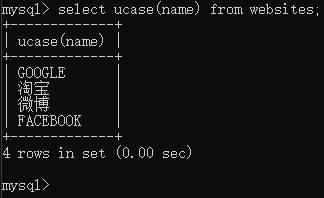
然后我们用自己的网页表做个测试,可以看到存储内容变成大写了
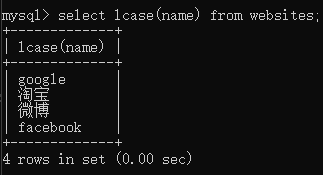
1 | select ucase(name) from websites; |
 ;
;
LCASE
定义
LCASE() 函数把字段的值转换为小写。
使用
SQL LCASE() 语法
1 | SELECT LCASE(column_name) FROM table_name; |
用于 SQL Server 的语法
1 | SELECT LOWER(column_name) FROM table_name; |
同样的,我们可以用websites表做个测试
1 | select lcase(name) from websites; |
 ;
;
MID
定义
MID() 函数用于从文本字段中提取字符。
使用
SQL MID() 语法
1 | SELECT MID(column_name[,start,length]) FROM table_name; |
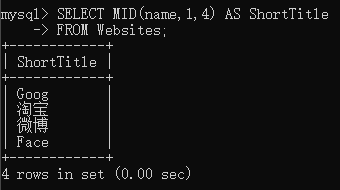
下面的 SQL 语句从 “Websites” 表的 “name” 列中提取前 4 个字符:
1 | SELECT MID(name,1,4) AS ShortTitle |
LEN
定义
LEN() 函数返回文本字段中值的长度。
使用
SQL LEN() 语法
1 | SELECT LEN(column_name) FROM table_name; |
MySQL 中函数为 LENGTH():
1 | SELECT LENGTH(column_name) FROM table_name; |
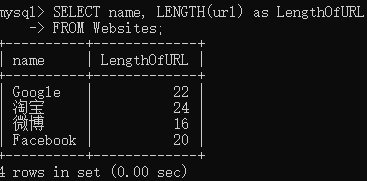
下面的 SQL 语句从 “Websites” 表中选取 “name” 和 “url” 列中值的长度:
1 | SELECT name, LENGTH(url) as LengthOfURL |
ROUND
定义
ROUND() 函数用于把数值字段舍入为指定的小数位数。
1 | SELECT ROUND(column_name,decimals) FROM TABLE_NAME; |
column_name 必需。要舍入的字段。
decimals 可选。规定要返回的小数位数。
使用
ROUND(X): 返回参数X的四舍五入的一个整数。
1 | SELECT ROUND(-1.23); |
得到-1
ROUND(X,D): 返回参数X的四舍五入的有 D 位小数的一个数字。如果D为0,结果将没有小数点或小数部分。
SELECT ROUND(1.298, 1);
得到1.3
SELECT ROUND(1.298, 0);
得到1
NOW
定义
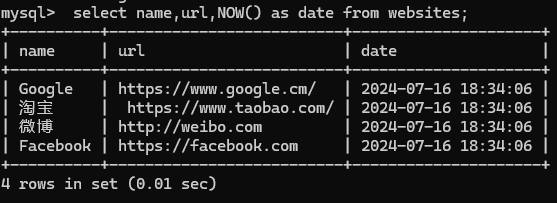
NOW() 函数返回当前系统的日期和时间。
使用
1 | select name,url,NOW() as date from websites; |
FORMAT()
定义
FORMAT() 函数用于对字段的显示进行格式化。
使用
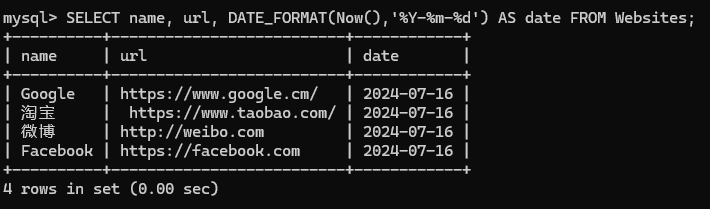
下面的 SQL 语句从 “Websites” 表中选取 name, url 以及格式化为 YYYY-MM-DD 的日期:
1 | SELECT name, url, DATE_FORMAT(Now(),'%Y-%m-%d') AS date FROM Websites; |
结语
本篇文章就到这里了,更多内容敬请期待,债见!


